
What Is Perceptron? Introduction, Definition & More
Perceptron is a commonly used term in the arena of Machine Learning and Artificial Intelligence. Being the most basic component of Machine Learning and Deep Learning technologies, the perceptron is the elementary unit of an Artificial Neural Network.
In this article, you will learn what is perceptron and compare perceptron vs neuron to understand how it is similar to the neurons in our brain. Breaking down the perceptron further, we will dive into its components, perceptron learning rule, perceptron in machine learning, and perceptron in a neural network.
What is Perceptron?
A perceptron is the smallest element of a neural network. Perceptron is a single-layer neural network linear or a Machine Learning algorithm used for supervised learning of various binary classifiers. It works as an artificial neuron to perform computations by learning elements and processing them for detecting the business intelligence and capabilities of the input data. A perceptron network is a group of simple logical statements that come together to create an array of complex logical statements, known as the neural network.
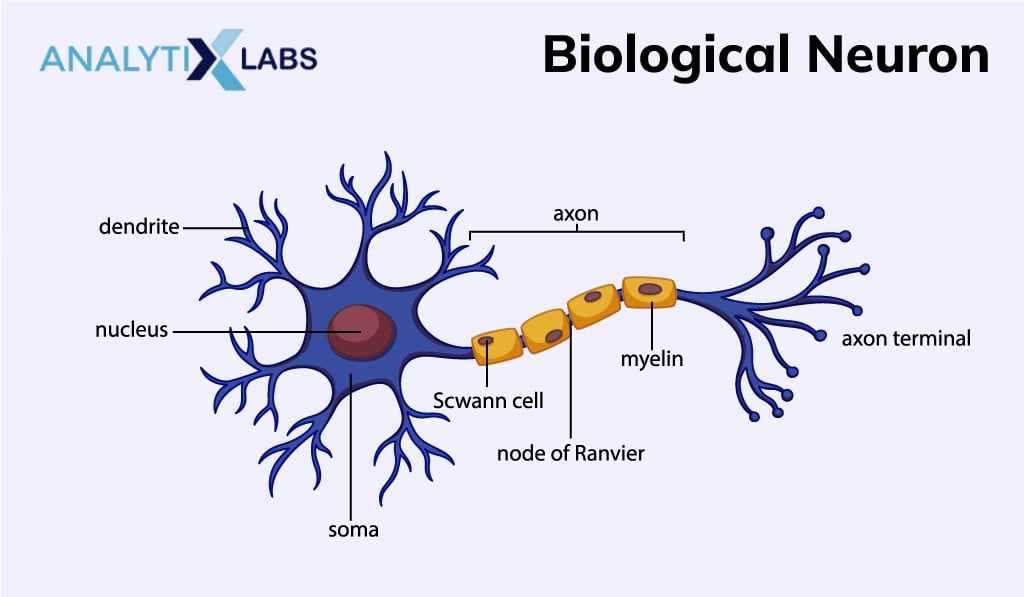
The human brain is a complex network of billions of interconnected cells known as Neurons. These cells process and transmit signals. Biological neurons respond to both chemical and electrical signals to create the Biological Neural Network (BNN). The input and output signals can either be excitatory or inhibitory, meaning that they can either increase or decrease the potential of the neuron to fire.
The structure of a biological neuron consists of a Synapse, dendrites, Soma or the cell body, and axon. All these components participate in the neural processing performed by neurons. Synapse connects an axon to another neuron and also processes the inputs. Dendrites receive the signals while the Soma sums up all the incoming signals. The transmission of signals to other neurons is carried by the axon. A Biological Neural Network slowly yet efficiently processes highly complex parallel inputs.
Artificial Neuron
An artificial neuron is based on a model of biological neurons but it is a mathematical function. The neuron takes inputs in the form of binary values i.e. 1 or 0, meaning that they can either be ON or OFF. The output of an artificial neuron is usually calculated by applying a threshold function to the sum of its input values.
The threshold function can be either linear or nonlinear. A linear threshold function produces an output of 1 if the sum of the input values is greater than or equal to a certain threshold, and an output of 0 if the sum of the input values is less than that threshold. A nonlinear threshold function, on the other hand, can produce any output value between 0 and 1, depending on the inputs.
An Artificial Neural Network (ANN) is built on artificial neurons and based on a Feed-Forward strategy. It is known as the simplest type of neural network as it continues learning irrespective of the data being linear or nonlinear. The information flow through the nodes is continuous and stops only after reaching the output node.
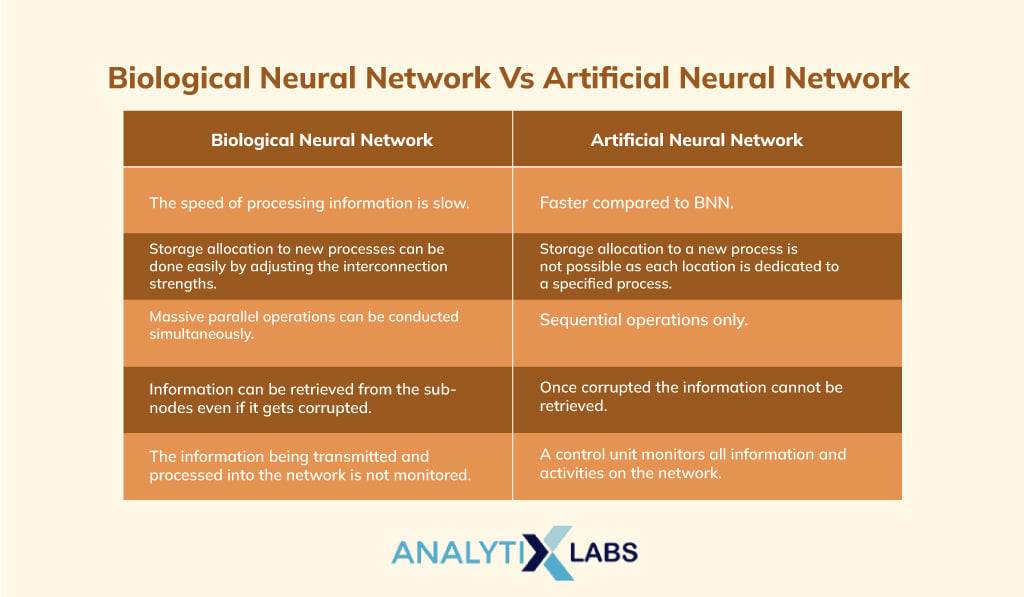
Biological Neural Network Vs Artificial Neural Network
The structure of artificial neurons is derived from biological neurons and the network is also formed on a similar principle but there are some differences between a biological neural network and an artificial neural network.
Perceptron Vs Neuron
The perceptron is a mathematical model of the biological neuron. It produces binary outputs from input values while taking into consideration weights and threshold values. Though created to imitate the working of biological neurons, the perceptron model has since been replaced by more advanced models like backpropagation networks for training artificial neural networks. Perceptrons use a brittle activation function to give a positive or negative output based on a specific value.
A neuron, also known as a node in a backpropagation artificial neural network produces graded values between 0 and 1. It is a generalization of the idea of the perceptron as the neuron also adds weighted inputs. However, it does not produce a binary output but a graded value based on the proximity of the input to the desired value of 1. The results are biased towards the extreme values of 0 or 1 as the node uses a sigmoidal output function. The graded values can be interpreted to define the probability of the input’s category.
Components of a Perceptron
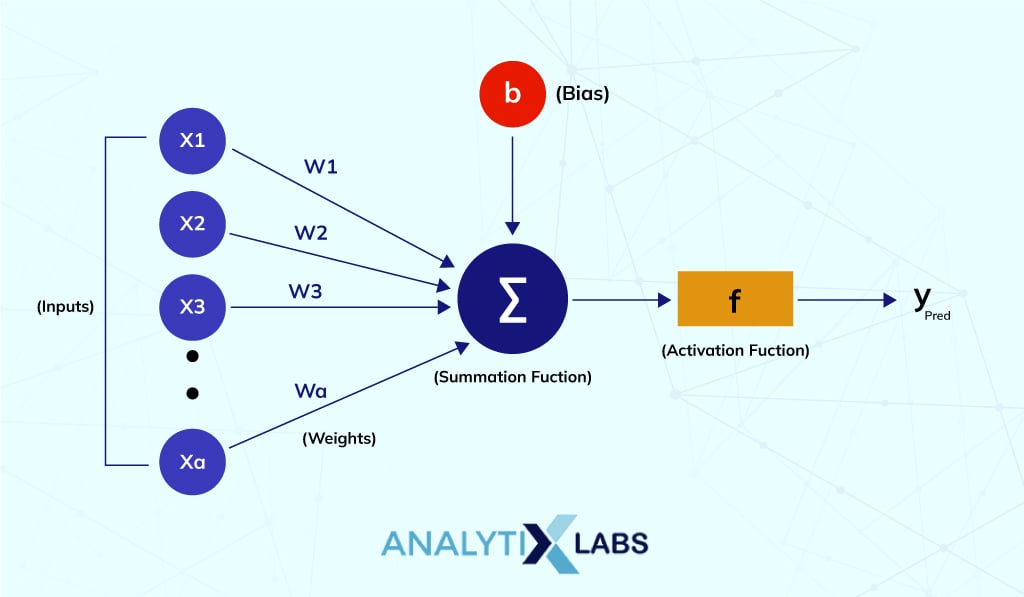
Each perceptron comprises four different parts:
- Input Values
: A set of values or a dataset for predicting the output value. They are also described as a dataset’s features and dataset.
- Weights:
The real value of each feature is known as weight. It tells the importance of that feature in predicting the final value.
- Bias:
The activation function is shifted towards the left or right using bias. You may understand it simply as the y-intercept in the line equation.
- Summation Function:
The summation function binds the weights and inputs together. It is a function to find their sum.
- Activation Function:
It introduces non-linearity in the perceptron model.
Why do we Need Weight and Bias?
Weight and bias are two important aspects of the perceptron model. These are learnable parameters and as the network gets trained it adjusts both parameters to achieve the desired values and the correct output.
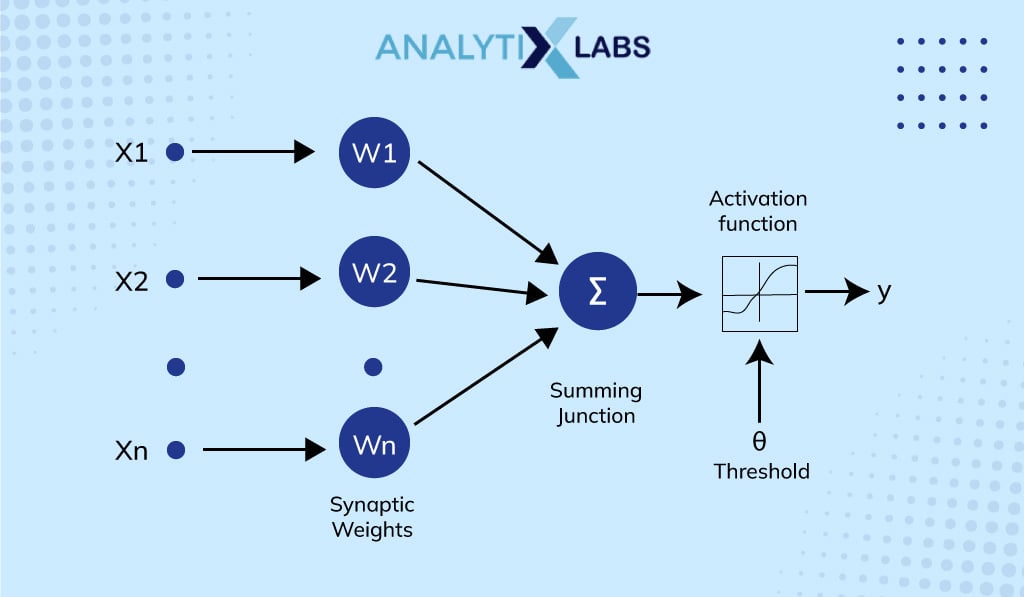
Weights are used to measure the importance of each feature in predicting output value. Features with values close to zero are said to have lesser weight or significance. These have less importance in the prediction process compared to the features with values further from zero known as weights with a larger value. Besides high-weighted features having greater predictive power than low-weighting ones, the weight can also be positive or negative. If the weight of a feature is positive then it has a direct relation with the target value, and if it is negative then it has an inverse relationship with the target value.
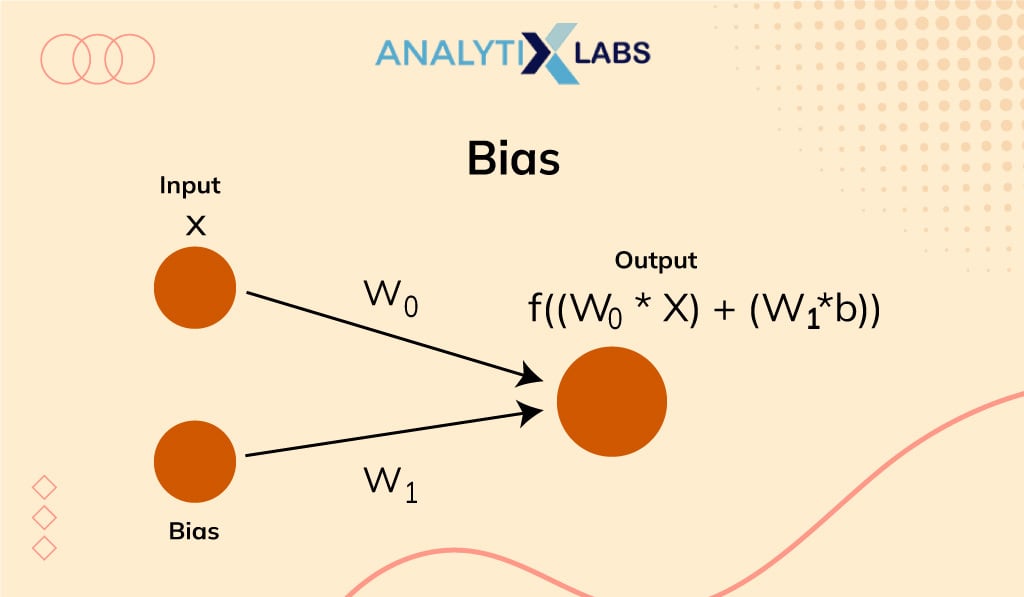
In contrast to weight in a neural network that increases the speed of triggering an activation function, bias delays the trigger of the activation function. It acts like an intercept in a linear equation. Simply stated, Bias is a constant used to adjust the output and help the model to provide the best fit output for the given data.
Perceptron Learning Rule
The late 1950s saw the development of a new type of neural network called perceptrons, which were similar to the neurons from an earlier work by McCulloch and Pitts. One key contribution by Frank Rosenblatt was his work for training these networks with perceptron learning rules. According to the rule, perceptron can learn automatically to generate the desired results through optimal weight coefficients.
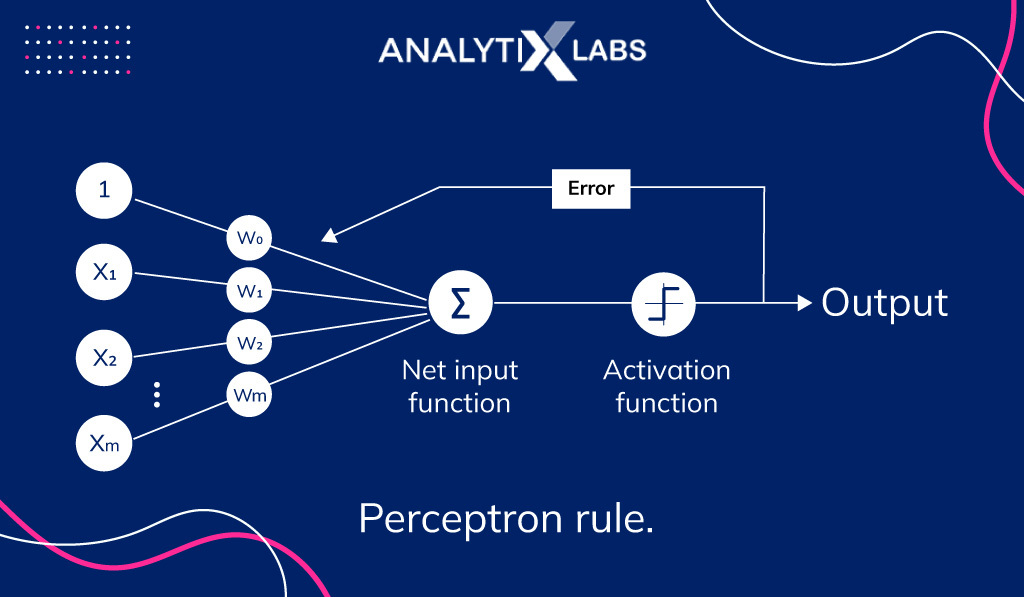
Rosenblatt defined four perceptron learning rules, that can be classified as follows:
Supervised Learning Algorithms
Gradient Descent
In order to optimize the weights of a perceptron in a machine learning model, there needs to be an adjustable function that can predict future outcomes. Weights and activation functions help with error reduction. Activation functions come into play because they help determine how much weight should go towards each input when prediction errors are calculated.
The more differentiable it becomes at predicting values based on past statistics about samples within its domain (trained data) the better it will be able to estimate accurate answers.

In this learning, the error gradient E impacts the adjustment of weights. An example of this learning is the backpropagation rule.
Stochastic
The term Stochastic is a mathematical term that refers to a variable process or an outcome that involves randomness and uncertainty. The perceptron in machine learning adjusts weights in a probabilistic fashion under this rule.
Unsupervised Learning Algorithms
Hebbian
A perceptron learning rule was proposed by Hebb in 1949. It uses a weight matrix, W to perform correlative adjustment of weights. Weight adjustment is done by transposing the output.

Competitive
In the perceptron learning algorithm, when an input pattern is sent to the entire layer of neurons all the units compete for space and time. The only way that a neuron can win against others in this type of competition is by having more efficient weights.
Perceptron in Machine Learning
Perceptron in machine learning is used for the supervised learning of the algorithm through various binary classification tasks. Also referred to as Artificial Neuron or neural network unit, a perceptron can learn to detect input data computations in business intelligence.
The perceptron model in neural networks is one of the simplest artificial neural networks. However, the perceptron learning algorithm is a type of supervised machine-learning system that uses binary classifiers for decision-making.
Binary Classifiers in Machine Learning
In Machine Learning, a binary classifier is used to decide whether input data can be represented as vectors of numbers and belongs to some specific category. Binary classifiers are linear because they take into account weight values along with features. It helps the algorithm determine the classification value or probability distribution around the prediction point.
The Perceptron in Neural Network
Neural networks are computational algorithms or models that understand the data and process information. As these artificial neural networks are designed as per the structure of the human brain, the role of neurons in the brain is played by the perceptron in a neural network.
The perceptron model in a neural network is a convenient model of supervised machine learning. Being the early algorithm of binary classifiers it incorporates visual inputs and organizes captions into one of two classes. Machine learning algorithms exploit the crucial element of classification to process, identify and analyze patterns. Perceptron algorithms help in the linear separation of classes and patterns based on the numerical or visual input data.
Perceptron Model
Developed for the first time in 1957 at Cornell Aeronautical Laboratory, United States the perceptron model was used for machine-driven image recognition. Being the first-ever artificial neural network it was claimed to be the most notable AI-based innovation.
The perceptron algorithm however had some technical constraints. Being single-layered the perceptron model was only applicable for linearly separable classes. The issue was later resolved by the discovery of multi-layered perceptron algorithms. Here is a detailed look at the types of perceptron models:
Single Layer Perceptron Model
A single-layer perceptron model is the simplest type of artificial neural network. It includes a feed-forward network that can analyze only linearly separable objects while being dependent on a threshold transfer function. The model returns only binary outcomes(target) i.e. 1, and 0.
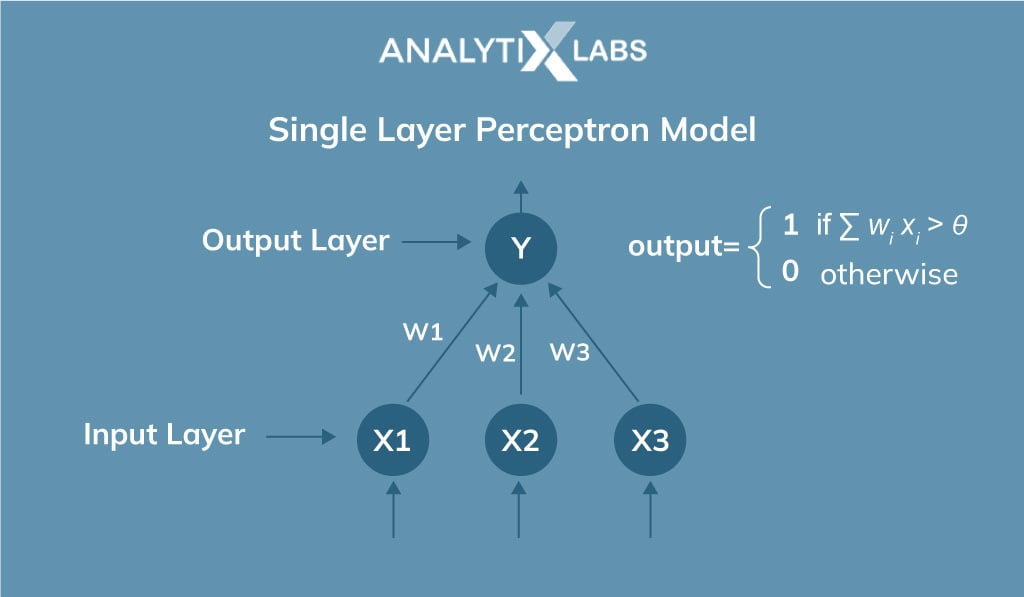
The algorithm in a single-layered perceptron model does not have any previous information initially. The weights are allocated inconsistently, so the algorithm simply adds up all the weighted inputs. If the value of the sum is more than the threshold or a predetermined value then the output is delivered as 1 and the single-layer perceptron is considered to be activated.

When the values of input are similar to those desired for its predicted output, then we can say that the perceptron has performed satisfactorily. If there is any difference between what was expected and obtained, then the weights will need adjusting to limit how much these errors affect future predictions based on unchanged parameters.

However, since the single-layer perceptron is a linear classifier and it does not classify cases if they are not linearly separable. So, due to the inability of the perceptron to solve problems with linearly non-separable cases, the learning process will never reach the point with all cases properly classified. The inability was brought to light by Minsky & Papert in 1969.
Multilayer Perceptron Model
A multi-layer perceptron model uses the backpropagation algorithm. Though it has the same structure as that of a single-layer perceptron, it has one or more hidden layers.
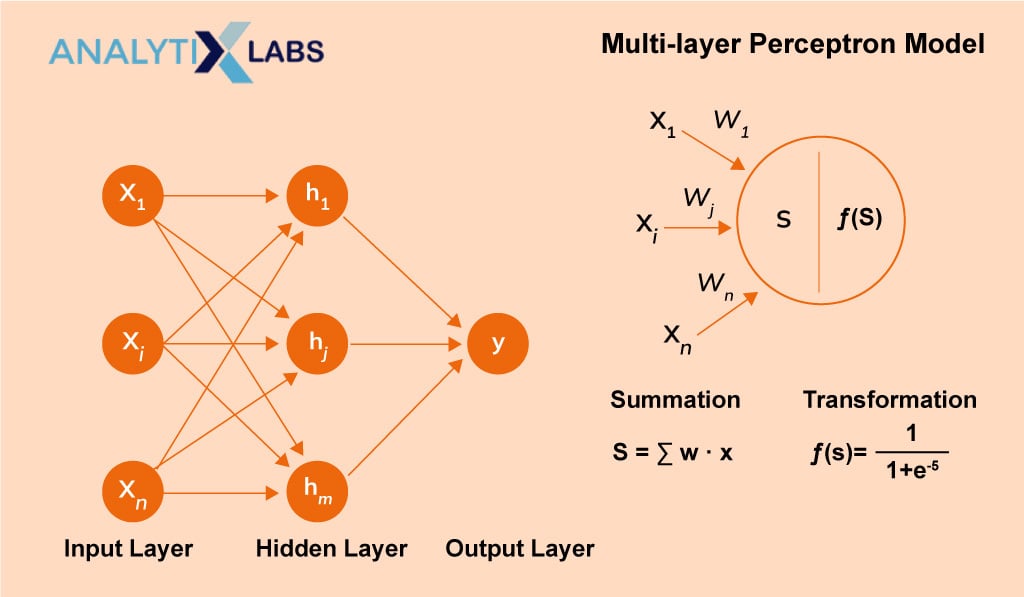
The backpropagation algorithm is executed in two phases:
- Forward phase-
Activation functions propagate from the input layer to the output layer. All weighted inputs are added to compute outputs using the sigmoid threshold.
- Backward phase-
The errors between the observed actual value and the demanded nominal value in the output layer are propagated backward. The weights and bias values are modified to achieve the requested value. The modification is done by apportioning the weights and bias to each unit according to its impact on the error.

Perceptron Function
Perceptron function ”f(x)” is generated by multiplying the input ‘x’ with the learned weight coefficient ‘w’. The same can be expressed through the following mathematical equation:

Limitations of the Perceptron Model
A perceptron model has the following limitations:
-
The input vectors must be presented to the network one at a time or in batches so that the corrections can be made to the network based on the results of each presentation.
-
The perceptron generates only a binary number (0 or 1) as an output due to the hard limit transfer function.
-
It can classify linearly separable sets of inputs easily whereas non-linear input vectors cannot be classified properly.
Future of Perceptron
Machine learning is an artificial intelligence technique that has been rapidly evolving for many years. Perceptron has been supporting the growth of artificial intelligence and machine learning technologies even during its development phase. It will continue to aid analytical behavior by processing data through pattern recognition algorithms.
Perceptron: Frequently Asked Questions
Why is perceptron used?
Perceptron is a linear classifier used for data classification into the two binary sections. Facilitating the supervised learning of binary classifiers, the perceptron algorithm learns and processes elements in the training set one at a time. It helps detect features from an input to derive business intelligence and classify the inputs as it enables machines to automatically learn coefficients of weight. Perceptron is commonly used for basic operations like data compression, data visualization, high-quality complex image recognition, and encryption.
What is meant by a perceptron in AI?
Perceptron in AI is an algorithm for processing single-layer binary classifiers. It is useful for supervised learning of algorithms as it automatically learns to optimize weight coefficients. The decision of whether a neuron is fired or not is made by multiplying weights with the input features. If the sum of the input signals and weights exceeds a certain threshold, the output is a signal or 1, if not, then there is no output or the signal is zero.
Additional resources you would like to read:














![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


