
Reinforcement Learning With (Deep) Q-Learning Explained
In this tutorial, we learn about Reinforcement Learning and (Deep) Q-Learning.
In two previous videos we explained the concepts of Supervised and Unsupervised Learning. Reinforcement Learning (RL) is the third category in the field of Machine Learning.
This area has gotten a lot of popularity in recent years, especially with video games where an AI learns to play games like chess, Snake, or Breakout.
We will cover:
- What Reinforcement Learning is
- What States / Actions / Rewards are
- What Q-Learning is
- An exmaple of Q-Learning
- Deep Q-Learning with Neural Networks
If you’d rather watch, you can view a video version of this tutorial here:
Mục Lục
Idea and Definition
The idea behind RL is that software agents learn from the environment by interacting with it and then receiving rewards or punishments for performing actions. With this approach the agent can teach itself to get better and improve its behavior in order to maximize its expected reward.
The concept of Reinforcement Learning is inspired from our natural experiences. Imagine you’re a child and you see fireplace for the first time. You like that it’s warm. It’s positive, so you get a positive reward.
 Learning in an environment
Learning in an environment
Let’s say you then reach out with your hand and try to touch the fire. Now your hand is too warm, so it hurts, leaving you with a negative reward (or punishment). From this experience you can learn that fire (the environment) can be good or bad (rewards/punishments) depending on how you interact with it (your actions).
And this is exactly how Reinforcement Learning works. It is the computational approach of learning from actions in an environment through rewards and punishments.
Q-Learning
One specific implementation of this approach is the Q-Learning algorithm. It is a value based approach based on the so called Q-Table.
The Q-Table calculates the maximum expected future reward, for each action at each state. With this information we can then choose the action with the highest reward.
Let’s look at a concrete example to make this more clear.
Let’s say we want to teach an AI how to play the Snake game. In this game the snake tries to reach and eat the food without hitting the wall or itself. We can list the actions and states in a Q-Table. The columns will be the four possible actions the snake can do, turning left, right, up, and down. And the state can be the current direction, so also left, right, up, and down. These are the rows.
We can add more states to describe the current situation. For example, we can describe the location of the food, and add the states food is left of the snake, right, up, or down.
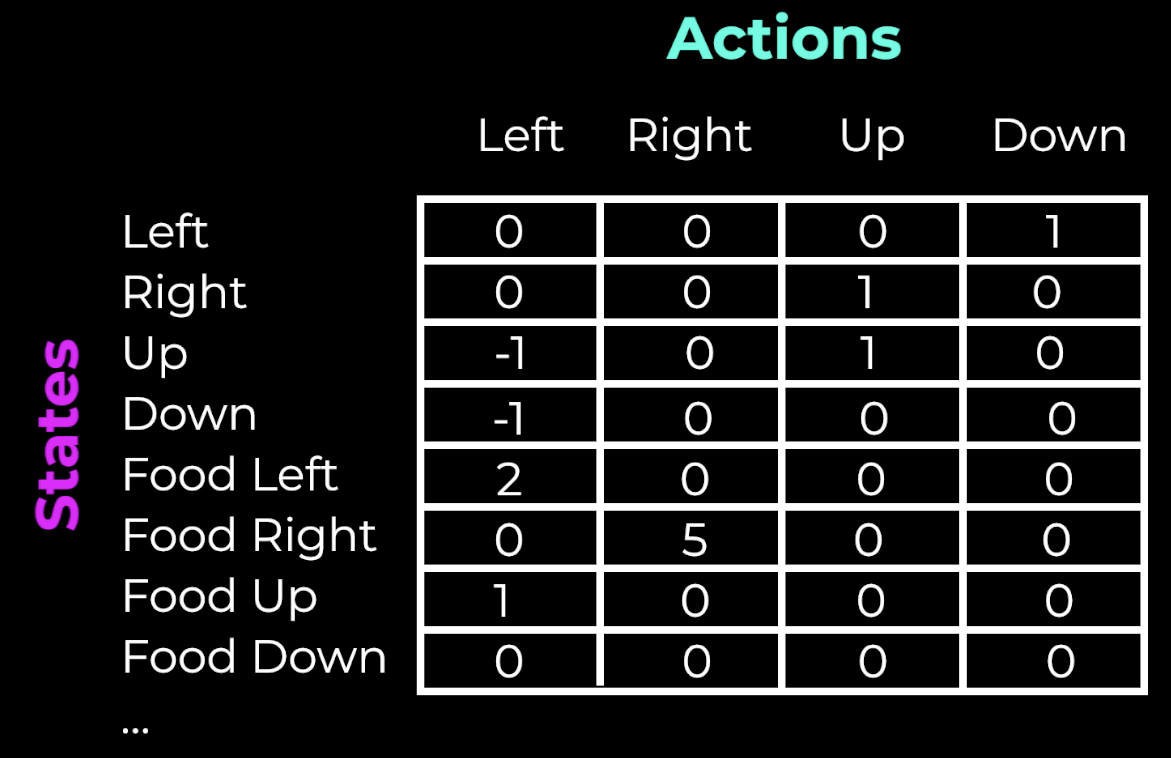 Q-Table
Q-Table
We could build up the state by adding more information, for example informations about the walls, but for simplicity we leave this out here. The more state information we add, the more information we have about the environment, but also the more complex our system gets.
With the rows and columns being defined, the value of each cell will be the maximum expected future reward for that given state and action. We call this the Q-value.
So far so good. But how do we calculate the Q value?
Q Learning algorithm
Here is the interesting part. We do not implement the Q value calculation in a fixed way. Instead, we improve the Q-table in an iterative approach. This is known as the training or learning process.
The Q-Learning algorithm works like this:
- Initialize all Q-values, e.g., with zeros
- Choose an action a in the current state s based on the current best Q-value
- Perform this action a and observe the outcome (new state s’).
- Measure the reward R after this action
- Update Q with an update formula that is called the Bellman Equation.
Repeat steps 2 to 5 until the learning no longer improves and we should end up with a helpful Q-Table. You can then consider the Q-Table as a “cheat sheet” that always tells the best action for a given state.
But you may be wondering how we can choose the best action in the beginning when all our values are 0?
Exploration vs. exploitation trade-off
This is where the exploration vs. exploitation trade-off comes into play. In the beginning we choose the action randomly so that the agent can explore the environment. But the more training steps we get, the more we reduce the random exploration and use exploitation instead, so the agent makes use of the information it has.
This trade-off is controlled in the calculations by a parameter that is usually called the epsilon (ɛ) parameter.
Reward
How we measure the reward is up to us. We should try to come up with a good reward system for the game. In case of the snake game, we can give a reward of 10 points if the snake eats an apple, a reward of -10 points if the snake dies, and 0 for every other normal move.
Now with all these elements we can inspect the Bellman equation:
The idea here is to update our Q value like this:
 Bellman equation
Bellman equation
The discount rate is a value between 0 and 1 and determines how much the agents cares about rewards in the distant future relative to those in the immediate future.
Now we all information we need, so that we can come up with a good Q-Table by using this iterative learning approach!
Deep Q Learning
Deep Q Learning uses the Q-learning idea and takes it one step further. Instead of using a Q-table, we use a Neural Network that takes a state and approximates the Q-values for each action based on that state.
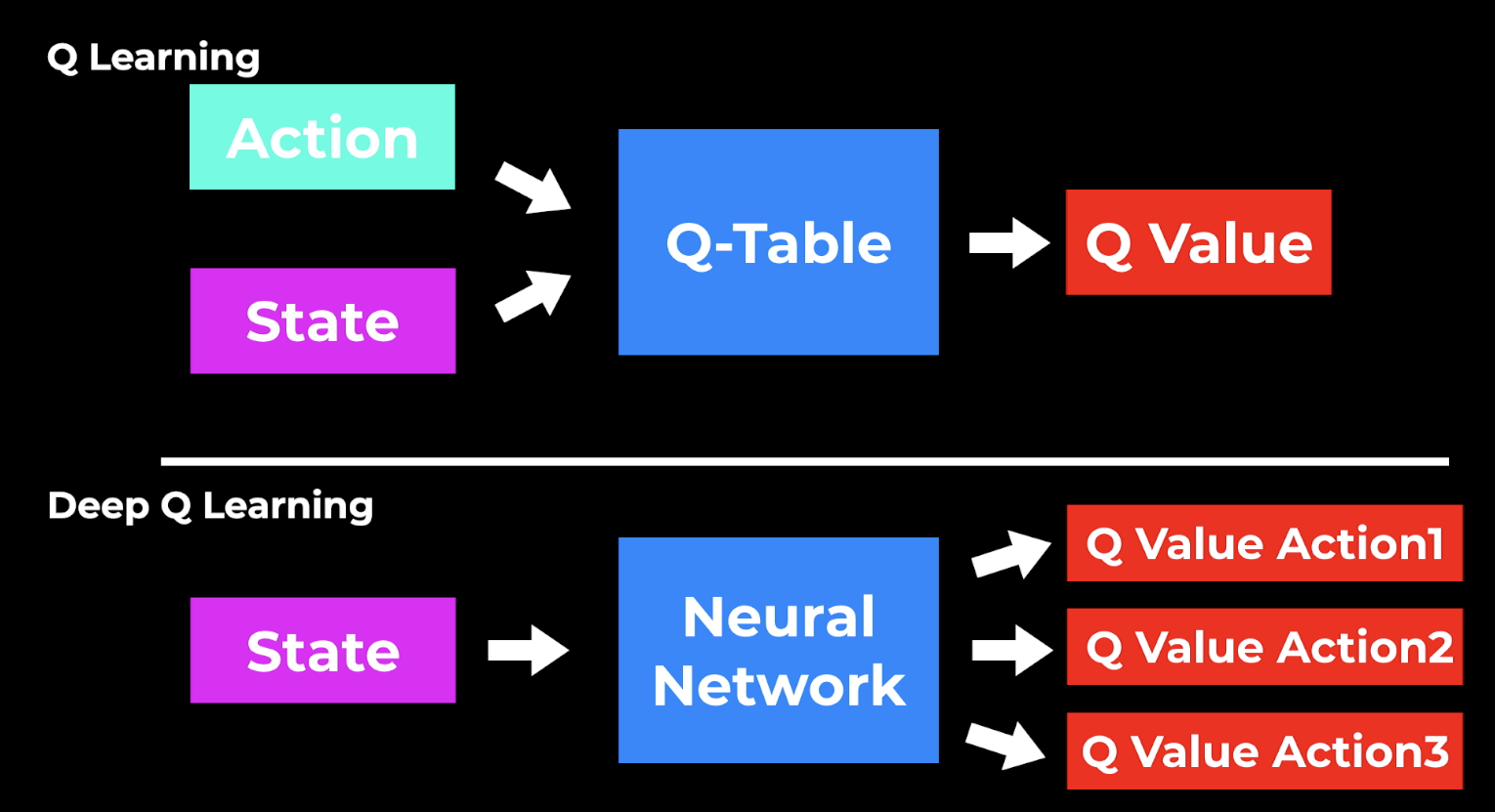 Q-Learning vs Deep Q-Learning
Q-Learning vs Deep Q-Learning
We do this because using a classic Q-table is not very scalable. It might work for simple games, but in a more complex game with dozens of possible actions and game states the Q-table will soon get complex and cannot be solved efficiently anymore.
So now we use a Deep Neural Network that gets the state as input, and produces different Q values for each action. Then again we choose the action with the highest Q-value. The learning process is still the same with the iterative update approach, but instead of updating the Q-Table, here we update the weights in the neural network so that the outputs are improved.
And this is how Deep Q-Learning works!
Final words
I hope this article could give you an easy introduction to Reinforcement Learning. If you enjoyed it, make sure to also watch the corresponding video on our YouTube channel, and share the article on Twitter!
Subscribe here














![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


