
Enterprise Data Warehouse: EDW Components, Key Concepts, and Architecture Types
Reading time:
14
minutes
Throughout the day we make many decisions relying on previous experience. Our brains store trillions of bits of data about past events and leverage those memories each time we face the need to make a decision. Like people, companies generate and collect tons of data about the past. And this data can be used to make better decisions.
While our brain serves to both process and store, companies need multiple tools to work with data. And one of the most important ones is an enterprise data warehouse or EDW.
In this article, we will discuss what an enterprise data warehouse is, its types and functions, and how it’s used in the data processing. We will define how enterprise warehouses are different from the usual ones, what types of data warehouses exist, and how they work. The focus is to provide information about the business value of each architectural and conceptual approach to building a warehouse.
Mục Lục
What is an enterprise data warehouse?
An Enterprise Data Warehouse (EDW) is a form of centralized corporate repository that stores and manages all the historical business data of an enterprise. The information usually comes from different systems like ERPs, CRMs, physical recordings, and other flat files. To prepare data for further analysis, it must be placed in a single storage facility. This way, different business units can query it and analyze information from multiple angles. But for any data to become actionable insights, it must go a long way. You can learn more about how data gets from sources to BI tools in our video about data engineering.


With a data warehouse, an enterprise can manage huge data sets, without administering multiple databases. Such practice is a futureproof way of storing data for business intelligence (BI), which is a set of methods/technologies for transforming raw data into actionable insights. With the EDW being an important part of it, the system is similar to a human brain storing information, but on steroids.
Enterprise data warehouse components
There are a lot of instruments used to set up an enterprise data warehousing platform. Let’s have a bird’s eye view of the purpose of each component and its functions.
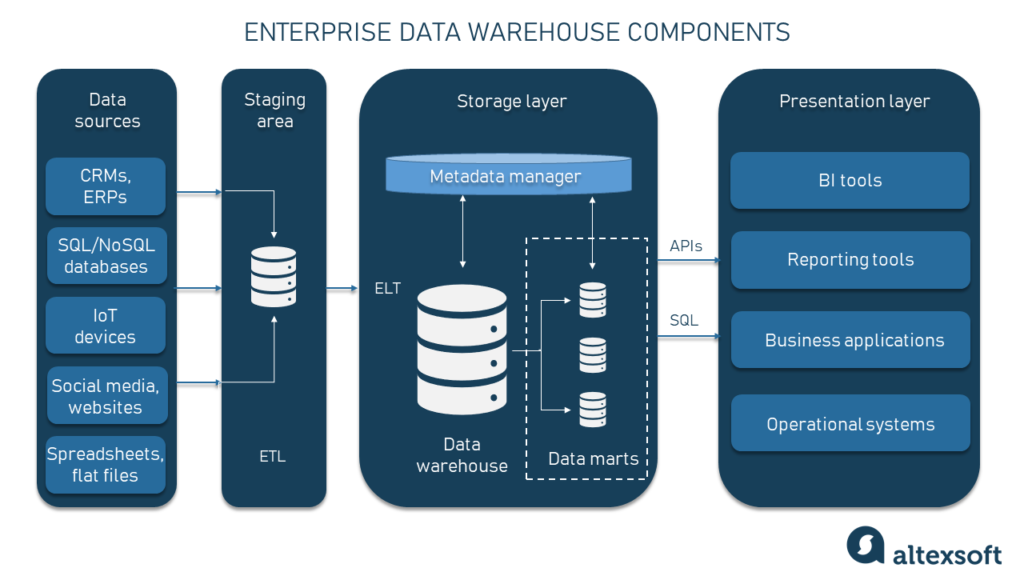
EDW components
Data sources. These are all the data sources where raw data originates and/or is stored. They can range from simple spreadsheets to flat files to relational SQL databases to IoT systems, and more.
Ingestion layer. There are two main approaches to pulling data out of sources and delivering it to a warehouse. Extract, transform, load (ETL) and extract, load, transform (ELT) tools connect to all the source data and perform its extraction, transformation, and loading into a centralized storage system for easy access and analysis. The distinction between ETL and ELT approaches is in the order of events. In ETL, the transformation happens in a staging area — before the data gets into an EDW. A more modern approach, ELT conducts all the transformation jobs inside a warehouse. Here the staging area is absent.
Staging area (optional). In the case of ETL, the staging area is the place data is transformed before EDW. Here, it will get cleansed, de-duplicated, split, joined, and converted into a unified format to fit a given data model of a warehouse. The staging area may also include tooling for data quality management.
Storage layer. The data is finally loaded into the storage space. With the ELT approach, it might still take some transformation here. But, at that stage, all the general changes will be applied, so the data will be loaded into its final model(s). As we mentioned, data warehouses are most often relational databases. DW will also include a database management system and additional storage for metadata.
Metadata module. Put simply, metadata is data about data. These are the explanations that give hints for users/administrators of what subject/domain this information relates to. This data can be technical meta (e.g., initial source), or business meta (e.g., region of sales). All the meta is stored in a separate module of EDW and is managed by a metadata manager. In some cases, there might be an additional layer built on top of the whole infrastructure to curate metadata like a data virtualization layer or a data fabric layer.
Data marts (optional). In some cases, an EDW can have a set of smaller subsections called data marts that are built specifically for a particular subject area, business function, or group of users. For example, there can be a separate data mart for marketing purposes and a data mart for a financial department.
Presentation layer. The final building block of an EDW comprises tools that give end users access to data. Also called the BI interface, this layer will serve as a dashboard for data visualization, business reporting, and pulling out separate pieces of information for such tasks as machine learning.
Now let’s figure out why such a repository is called the enterprise data warehouse, not just a data warehouse.
Enterprise data warehouse vs usual data warehouse: The key differences
By its fashion, any data warehouse is a database that is always connected with raw-data sources via data integration tools on one end and analytical interfaces on the other. They provide storage capacities as well as mechanisms to transform data, move it, and present it to the end user. If so, why do we isolate the enterprise form for discussion?
The difference between a usual data warehouse and an enterprise one is in its much wider architectural diversity and functionality. Because of the complex structure and size, EDWs are often decomposed into smaller databases, so end users are more comfortable querying these smaller databases. Considering this, we’re focusing on an enterprise warehouse to cover the whole spectrum of functionality.
However, the size of a warehouse isn’t the only thing that defines its technical complexity, the requirements for analytical and reporting capabilities, the number of data models, and the data itself. So, to understand what makes a warehouse what it is, let’s dive into its core concepts and functionality.
Enterprise data warehouse concepts and functions
With all the bells and whistles, at the heart of every warehouse lay basic concepts and functions. These pillars define a warehouse as a technological phenomenon.
Serves as the ultimate storage. An enterprise data warehouse is a unified repository for all corporate business data ever occurring in the organization.
Reflects the source data. EDW sources data from its original storage spaces like Google Analytics, CRMs, IoT devices, etc. If the data is scattered across multiple systems, it’s unmanageable. So, the purpose of EDW is to provide the likeness of the original source data in a single repository. As there is always new, relevant data generated both inside and outside the company, the flow of data requires a dedicated infrastructure to manage it before it enters a warehouse.
Stores structured data. The data stored in an EDW is always standardized and structured. This makes it possible for the end users to query it via BI interfaces and form reports. And this is what makes a data warehouse different from a data lake. Data lakes are used to store unstructured data for analytical purposes. But unlike warehouses, data lakes are used more by data engineers and data scientists to work with big sets of raw data.
Subject-oriented data. The main focus of a warehouse is business data that can relate to different domains. To understand what the data relates to, it’s always structured around a specific subject called a data model. An example of a subject can be a sales region or total sales of a given item. Additionally, metadata is added to explain in detail where every piece of information comes from.
Time-dependent. The data collected is usually historical data, because it describes past events. To understand when and for how long a certain tendency took place, the prevailing part of stored information is usually divided into time periods.
Non-volatile. Once placed in a warehouse, the data is never deleted from it. The data can be manipulated, modified, or updated due to source changes, but it’s never meant to be erased, at least by the end users. As we speak about historical data, deletions are counterproductive for analytical purposes. Yet general revisions may occur once in a few years to get rid of irrelevant data.
With the base principles, we’ll look at the implementation types of EDWs.
Types of enterprise data warehouse
Considering EDW functions, there is always some room for discussion on how to design it technically. In the case of data storage and processing, they are specific and distinct to different kinds of businesses. Depending on the amount of data, analytical complexity, security issues, and budget, of course, there is always an option on how to set up your system.
On-premises data warehouse
An on-premises data warehouse is considered a classic variant for an EDW that has its local dedicated hardware and software capabilities for unified data storage. When data is stored on physical servers, you don’t have to set up data integration tools between multiple databases. Instead, EDW can be connected with data sources via APIs to constantly source information and transform it in the process. So, all the work is done either in the staging area (the place where data is transformed before loading into the DW) or in the warehouse itself.
A classic data warehouse is considered superlative to a virtual one (that we discuss below) because there is no additional layer of abstraction. It simplifies the work for data engineers and makes it easier to manage data flow on the preprocessing side, as well as actual reporting.
The drawbacks of the classic warehouse depend on the actual implementation, but for most businesses these are:
- expensive technological infrastructure (both hardware and software) and
- the necessity to hire a team of data engineers and DevOps specialists to set up and maintain the whole data platform.
When to use: Such an EDW type is appropriate for organizations of all sizes that want to process their data securely and make the most out of it. Classic warehouses allow for morphing into different architectural styles of the data platform and scaling up and down on purpose while maintaining data privacy concerns.
Virtual data warehouse
A virtual data warehouse is a type of EDW used as an alternative to a classic warehouse. Essentially, these are multiple databases connected virtually, so they can be queried as a single system.
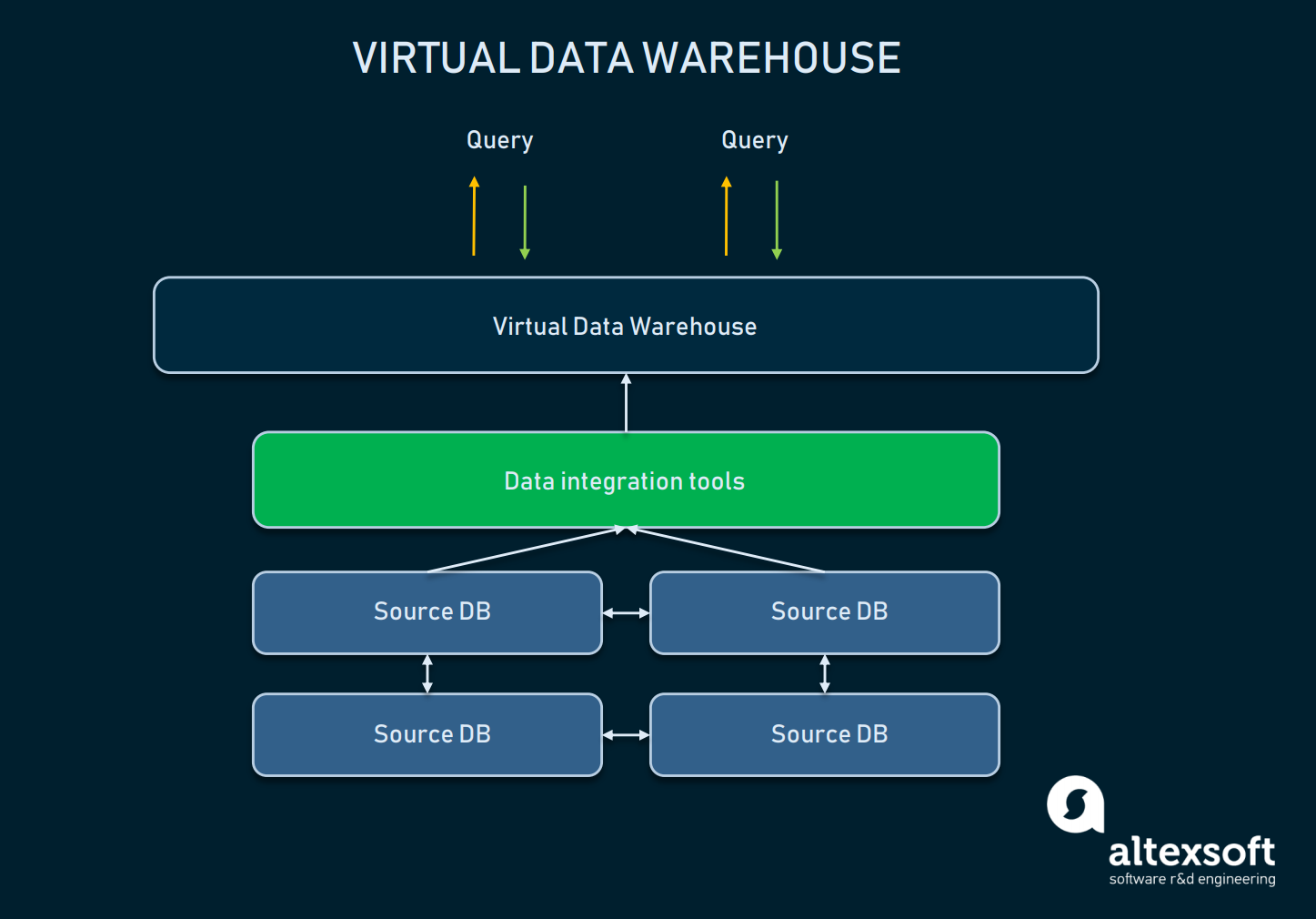
A scheme of relations between the abstraction of virtual DW and source databases
The data can stay in its sources: It isn’t moved physically anywhere but can still be pulled with the help of analytical tools. Virtual warehouses can be used if you don’t want to mess with all the underlying infrastructure, or the data you have is easily manageable as it is. However, such an approach has many drawbacks:
- Multiple databases will require constant software and hardware maintenance and costs.
- The data stored in a virtual DW still requires transformation software to make it digestible for the end users and reporting tools.
- Complex data queries may take too much time, as the required pieces of data may be placed in two separate databases.
When to use: Virtual EDWs are suitable for businesses that have raw data in a standardized form that doesn’t require complex analytics. It also fits organizations that don’t use BI systematically or want to start with it.
Cloud Data Warehouse
A cloud data warehouse is a central repository for different information hosted in the cloud. In this case, a database is delivered as a managed service by a cloud provider and is optimized for analytics, scale, and usability.
Cloud warehouses typically consist of compute, storage, and client (service) layers. In the compute layer, there are multiple compute clusters with nodes processing queries in parallel. The storage layer, as the name suggests, keeps all types of information. The client layer is responsible for data management activities.
In this case, cloud warehouse architecture has the same benefits as any other cloud service. Its infrastructure is typically maintained for you, meaning you don’t need to set up your own servers, databases, and tooling to manage it. The price for such a service will depend on the amount of memory and computing capabilities required for querying.
The only aspect you might be concerned about in terms of a cloud warehouse platform is data security. Your business data is a sensitive thing. So, you want to check if the vendor you have chosen can be trusted to avoid breaches. This doesn’t necessarily mean that an on-premise warehouse is more secure, but in this case, the safety of your data is in your hands.
When to use: Cloud data warehouse platforms are a great choice for organizations of any size. If you need everything set up for you, including managed data integration, DW maintenance, and BI support.
Enterprise Data Warehouse Architecture
While there are many architectural approaches that extend warehouse capabilities in one way or another, we will focus on the most essential ones. Without diving into too much technical detail, the whole data pipeline can be divided into three layers:
- Raw data layer (data sources)
- Warehouse and its ecosystem
- User interface (analytical tools)
The tooling that concerns data Extraction, Transformation, and Loading into a warehouse is a separate category of tools known as ETL. Also, under the ETL umbrella, data integration tools perform manipulations with data before it’s placed in a warehouse. These tools operate between a raw data layer and a warehouse.
When the data is loaded into a warehouse, it can also be transformed. So, the warehouse will require certain functionality for cleaning/standardization/dimensionalization. These and other factors will determine architecture complexity. We will look at the EDW architecture from the standpoint of growing organizational needs.
One-tier architecture
Given that data integration is well-configured, we can choose our data warehouse. In most cases, a data warehouse is a relational database with modules to allow multidimensional data or one that can separate some domain-specific information for easier access. In its most primitive form, warehousing can have just one-tier architecture.
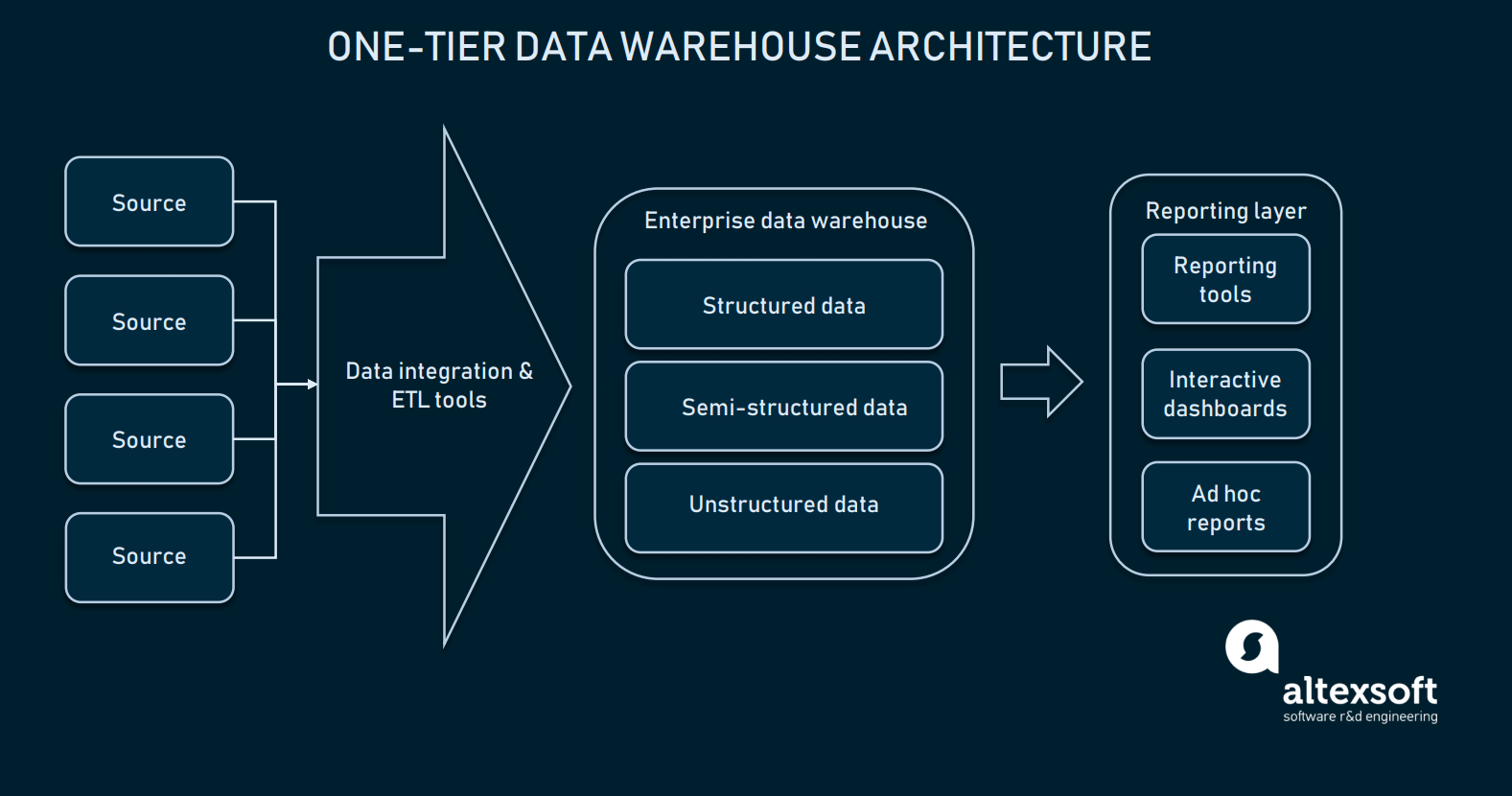
The reporting layer is connected directly with the whole database of EDW
One-tier architecture for EDW means that you have a database directly connected with the analytical interfaces where the end user can make queries. Setting the direct connection between an EDW and analytical tools brings several challenges:
- Traditionally, you can consider your storage a warehouse starting from 100GB of data. Working with it directly may result in messy query results, as well as low processing speed.
- Querying data right from the DW may require precise input so that the system will be able to filter out non-required data. Which makes dealing with presentation tools a little difficult.
- Limited flexibility/analytical capabilities exist.
Additionally, the one-tier architecture sets some limits to reporting complexity. Such an approach is rarely used for large-scale data platforms, because of its slowness and unpredictability. To perform advanced data queries, a warehouse can be extended with low-level instances that make access to data easier.
Two-tier architecture (data mart layer)
In two-tier architecture, a data mart level is added between the user interface and EDW. A data mart is a low-level repository that contains domain-specific information. Simply put, it’s another, smaller-sized database that extends EDW with dedicated information for your sales/operational departments, marketing, etc.
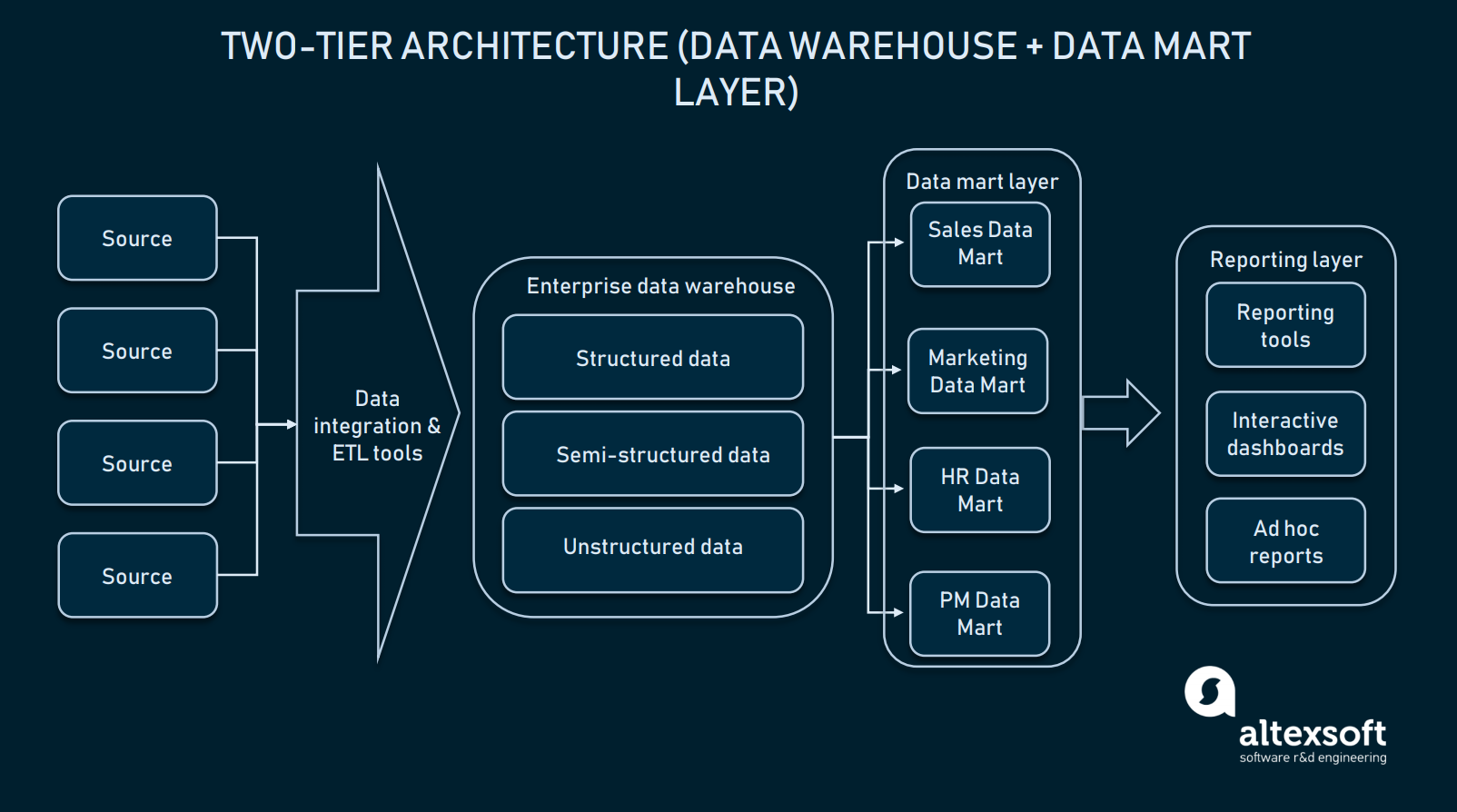
In two-tier architecture, an EDW is extended by data marts to provide domain-specific data
Creating a data mart layer will require additional resources to establish hardware and integrate those databases with the rest of the data platform. But, such an approach solves the problem with querying: Each department will access required data more easily because a given mart will contain only domain-specific information. In addition, data marts will limit the access to data for end users, making EDW more secure.
Three-tier architecture (Online analytical processing)
On top of the data mart layer, enterprises also use online analytical processing (OLAP) cubes. An OLAP cube is a specific type of database that represents data from multiple dimensions. While relational databases represent data in just two dimensions (think of Excel or Google Sheets), OLAP allows you to compile data in multiple dimensions and move between dimensions.
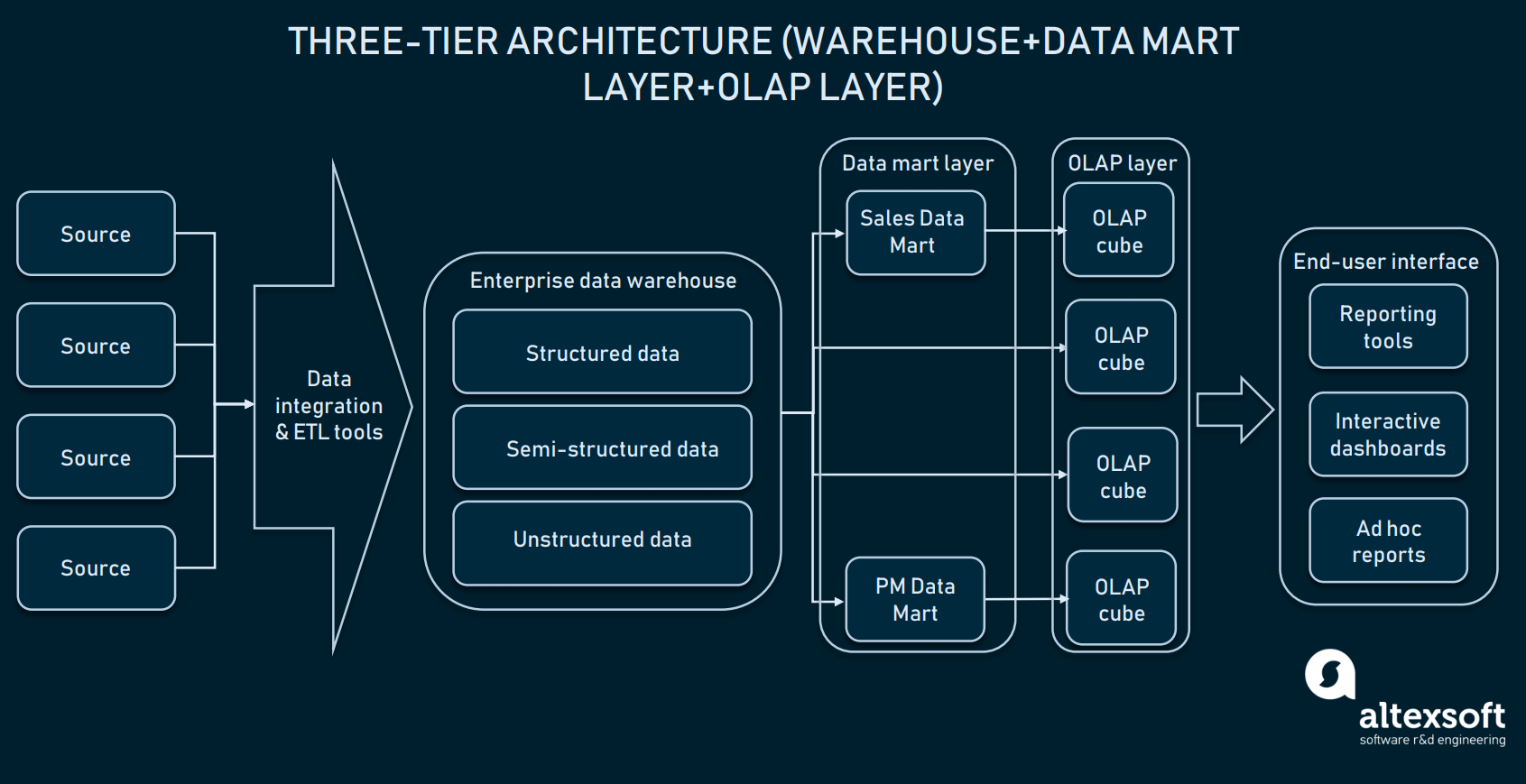
OLAP cubes layer may source information from distributed marts or directly from EDW
It’s pretty difficult to explain in words, so let’s look at this handy example of what a cube can look like.
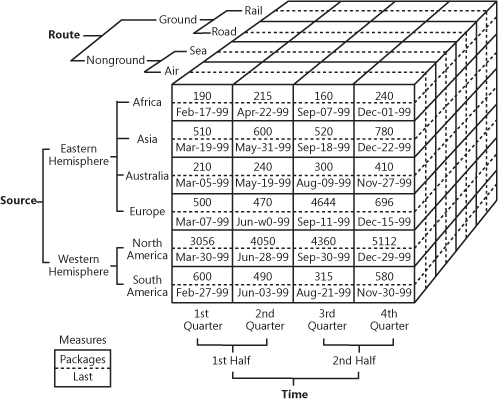
OLAP cube demonstrating multidimensional sales data
Source: oreilly.com
So, as you can see, a cube adds dimensions to the data. You may think of it as multiple Excel tables combined with each other. The front of the cube is the usual two-dimensional table, where the region (Africa, Asia, etc.) is specified vertically, while sales numbers and dates are written horizontally. The magic begins when we look at the upper facet of the cube, where sales are segmented by routes and the bottom specifies time-period. That’s known as multidimensional data.
The business value of OLAP is that it allows users to slice and dice the data to compile detailed reports. As long as the cubes are optimized to work with warehouses, they can be used both directly with an EDW to give access to all the corporate data or with each data mart specifically. In terms of implementation, nearly all warehouse providers offer OLAP as a service. As an example, check Microsoft documentation on their OLAP offer.
On that point, we have discussed a high-level design of an EDW applied to organizational needs. Now we’re going to drill down into technical components that a warehouse may include.
Data Warehouse vs Data Lake vs Data Mart
Speaking about data storage architecture, we have to mention such options as using a data mart or a data lake instead of a warehouse. Frequently conflated, we’ll elaborate on the definitions.
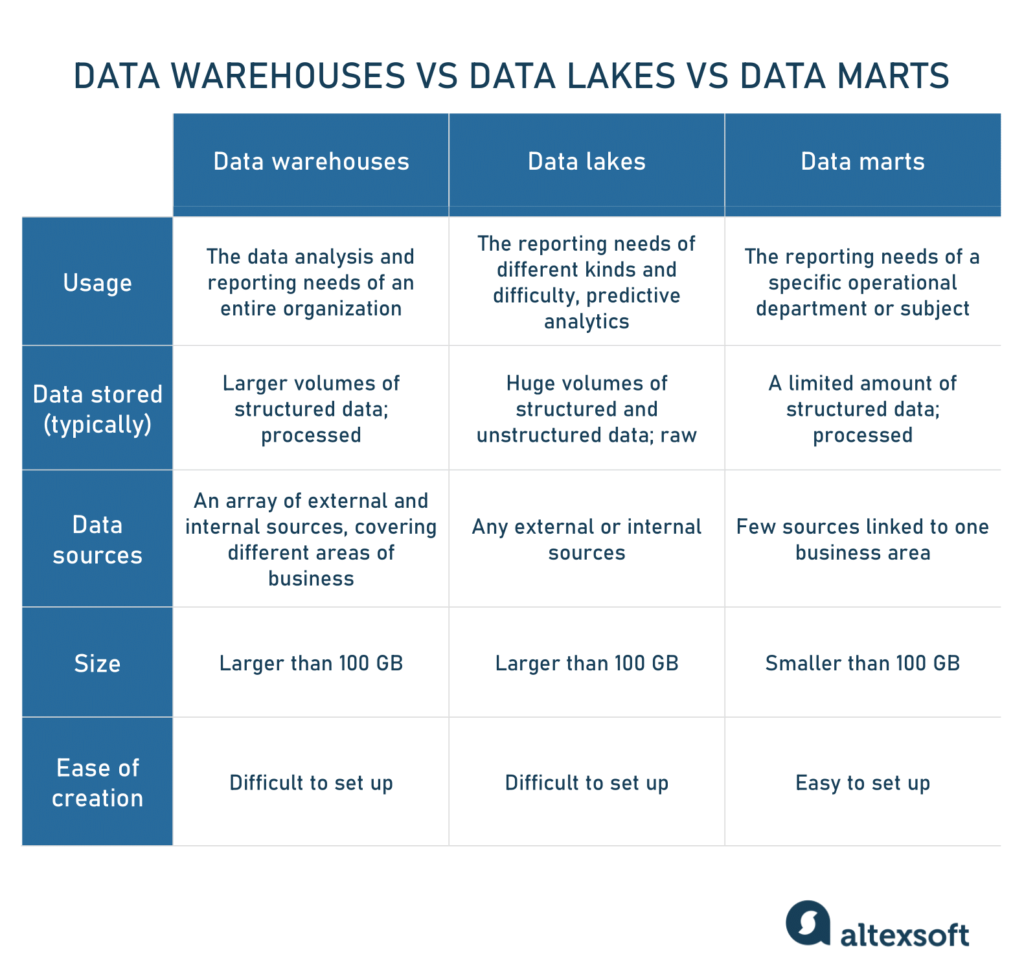
Comparison table of data warehouses vs data lakes vs data marts
Data warehouses, in their traditional form, are meant to store structured data presented fitting nicely in columns and rows so that it’s easier for querying tools and end users can get comprehensive results. Warehouses, mostly used for BI, usually vary in size between 100GB and infinity. They get data from a big number of external and internal sources, covering different business areas. Speaking of on-premises data warehouses, it may take months to complete their configuration.
Data lakes, on the other hand, are used to store massive amounts of different information including structured, unstructured, and semi-structured data in their raw formats. Lakes are often leveraged for machine learning, big data processing, or data mining purposes. For the last couple of years, data lakes have been used for BI: Raw data is loaded into a lake and transformed, which is an alternative to the ETL process. While this approach has its pros and cons, data lakes can be too messy for reaching structured data. By the way, there’s also a new, hybrid variant called a data lakehouse.
There may also be some confusion with the whole data warehouse vs data mart thing.
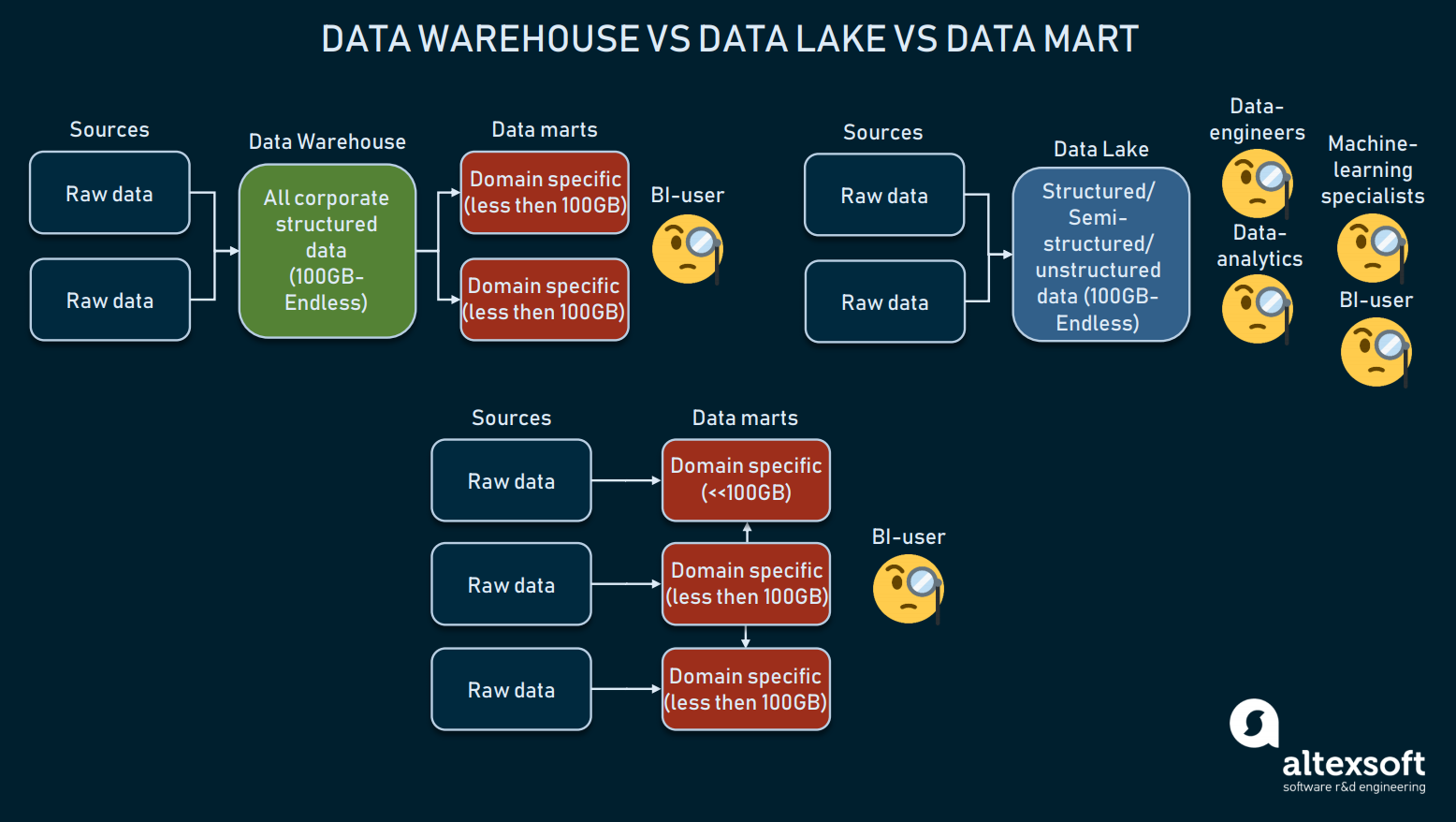
The comparison of three data storage forms
Data marts are subject-oriented relational databases that contain only a subset of DW data that is specific to a particular business department of an enterprise, e.g., a financial department. They can also be used as an alternative to DW. But, because of their small size (usually less than 100GB), data marts can hardly be used by enterprises. More often, data marts are used to segment a large DW into more operable segments. Data marts get information from relatively few sources, typically contain structured data, and take less time for setup — normally 3 to 6 months for on-premise solutions.
Enterprise data warehousing technologies
Understanding what enterprise data warehouse tools exist can help you figure out what actually fits your data platform requirements. Planning to set up a warehouse may take years of planning and testing, because of the scale of it in a most basic form.
As a business owner, you might be confused by the number of options and technologies used, so it’s vital to consult with experts in the field of warehousing, ETL, and BI. While experts can help you with the technical aspect, to define the business purpose, speak with the ones who will use the actual data in their work.
In recent times, cloud/cloudless technologies have become more of a standard for setting up organization-level technologies. You’ll find countless providers on the market that offer data warehousing-as-a-service, meaning you will use the computation power and space presented by cloud providers. And in most cases, such providers offer fully-managed, scalable warehousing as a part of their BI tooling.
Here are a few most popular cloud data warehouse products.
Amazon Redshift is a cloud-based enterprise data warehouse that is a part of Amazon’s cloud-computing platform. It allows for concurrent processing of large amounts of data depending on the demands of the company. While being a public cloud provider, Redshift is more self-managed, meaning you will need data engineers to perform resource and server management. As far as the pricing, you can start at $0.25 per hour and scale up to petabytes of data and thousands of concurrent users.
Google BigQuery is a multi-cloud data warehouse that provides capabilities for querying a large amount of data simultaneously by different users. It is a serverless technology, meaning all the management is taken care of for you, and it has separated compute and storage layers. BigQuery is highly performant and scalable. As far as the pricing, you can go either with flat-rate or on-demand subscriptions.
Snowflake is a more serverless cloud data warehouse built on top of the AWS technologies. Since it’s provided as a SaaS solution, you don’t have to configure any virtual or physical hardware as these tasks are taken care of by a provSnowflake has gained popularity for providing flexible, fast, and easy-to-use data storage and analytic solutions. As a user, you just choose the number and the size of compute clusters. The pricing page will guide you to the provider’s offerings.
More information about cloud data warehouses, their performance, integration capabilities, etc., you can find in our dedicated article comparing the key players on the cloud enterprise data warehousing market.














![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


