
Early History of the World-Wide Web: Origins and Beyond
The World-Wide Web is a product of the continuous search for innovative ways of sharing information. This paper describes early historical aspects of the World-Wide Web development and outlines some of the alternative methods of universal information sharing through hypertext, such as the Xanadu project. It also discusses the basic structure of the Web and the Xanadu system to illustrate key attributes of such global information networks.
Mục Lục
What is the World-Wide Web?
People have dreamed of a universal information database since late nineteen forties. In this collection, not only would the data be accessible to people around the world, but it would also “easily link to other pieces of information, so that only the most important data would be quickly found by a user.”KH
Only at the end of the twentieth century had the technology caught up to make such systems possible. The most popular system of this kind is the World-Wide Web, originally referred to as the WWW and now simply called the Web. The official description defines the Web as a “wide-area hypermedia information retrieval initiative aiming to give universal access to a large universe of documents.”KH In simpler terms, the it is an Internet-based computer network that allows users on one computer to access information stored on another through a series of interconnected networks.
Structure of the Web
The Web project is based on the principle of universal readership: “if information is available, then any (authorized) person should be able to access it from anywhere in the world.”JL The Web’s implementation follows a standard client-server model. In this model, a user relies on a program (the client) to connect to a remote machine (the server), where the data is stored. The architecture of the Web (see Figure 1) is the one of clients (a.k.a. browsers), such as Firefox or Internet Explorer, “which know how to present data but not what its origin is, and servers, which know how to extract data”, but are ignorant of how it will be presented to the user.TC2
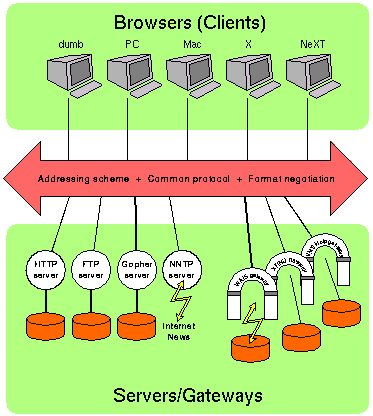
One of the main features of Web documents is their hypertext structure (see Figure 2). For instance, a particular reference can be represented by underlined text or an icon. “The user clicks on it with the mouse, and the referenced document appears.”BCG This method makes copying of information unnecessary: data needs only to be stored once, and all referenced to it can be linked to the original document.
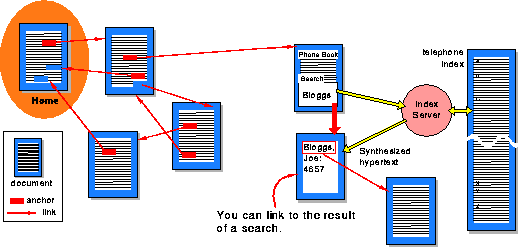
History of hypertext
The term hypertext was coined by Ted Nelson in his book “Literary Machines,” where he defined it as “non-sequential writing,” and only later it became considered a medium limited to computers.DH The earliest electronic model of such system was published in 1945 by Vannevar Bush. In his reference to the Bush’s article, David Hirmes writes:
By 1945, Bush had realized that an era of information was approaching. He commented: “The summation of human experience is being expanded at a prodigious rate, [but] the means we use for threading through the consequent maze to the momentarily important item is the same as was used in the days of square-rigged ships.”
Bush wrote of a “memex”, a conceptual machine that could store vast amounts of information, in which a user had the ability to create information “trails”: links of related text and illustrations. This trail could then be stored and used for future reference. Bush believed that using this associative method of information gathering was not only practical in its own right, but was closer to the way the mind ordered information.DH
Although “memex” was never implemented, in 1960 it inspired Ted Nelson to develop the modern version of hypertext. In his newsletter Nelson writes:
[It occurred to me] that the future of humanity is at the interactive computer screen, that the new writing and movies will be interactive and interlinked. It will be united by bridges of transclusion and we need a world-wide network to deliver it with royalty.TN2
Learning from Ted Nelson’s ideas, Tim Berners-Lee of CERN conceived the idea of the World-Wide Web in 1989.RCH
Origins of the Web
The World-Wide Web began in March 1989 at CERN. (CERN was originally named after its founding body the “Conseil Europeen pour la Recherche Nucleaire,” and is now called “European Laboratory for Particle Physics.”)GL
“CERN is a meeting place for physicists from all over the world, who collaborate on complex physics, engineering and information handling projects.”CERN1 Thus, the need for the Web system arose “from the geographical dispersion of large collaborations, and the fast turnover of fellows, students, and visiting scientists,” who had to get “up to speed on projects and leave a lasting contribution before leaving.”BCG
CERN possessed both the financial and computing resources necessary to start the project. In the original proposalTC1 Berners-Lee outlined two phases of the project:
- First, CERN would “make use of existing software and hardware as well as implementing simple browsers for the user’s workstations, based on an analysis of the requirements for information access needs by experiments.”
- Second, they would “extend the application area by also allowing the users to add new material.”
Berners-Lee expected each phase to take three months “with the full manpower complement”: he was asking for four software engineers and a programmer. The proposal talked about “a simple scheme to incorporate several different servers of machine-stored information already available at CERN.” This “scheme” was to use hypertext to provide “a single user-interface to many large classes of stored information such as reports, notes, data-bases, computer documentation and on-line systems help.”RCH
Set off in 1989, the Web quickly gained great popularity among Internet users. For instance, at 11:22 am of April 12, 1995, the Web server at the SEAS of the University of Pennsylvania “responded to 128 requests in one minute. Between 10:00 and 11:00, it responded to 5086 requests in one hour, or about 84 per minute,”CB At the time, that was a lot! Even years after its creation, the Web continued to expand: in December 1994 the Web was “growing at roughly 1 per cent a day — a doubling period of less than 10 weeks.”NS
As popular the Web became, it is not the only possible implementation of the hypertext concept. In fact, the theory behind the Web was based on a more general project “Xanadu,” that was being developed by Ted Nelson and never quite achieved take-off velocity.
What is Xanadu?
As described in the list of Frequently Asked Questions about Xanadu,XU Xanadu was the “original hypertext and interactive multimedia system.” Furthermore,
Xanadu is an overall paradigm – an ideal and general model for all computer use, based on sideways connections among documents and files.
It is intended to be especially free and fair, where all authors and readers are considered equal. It is a complete business system for electronic publishing based on this ideal with a win-win set of arrangements, contracts and software for the sale of copyrighted material in large and small amounts.
Ted Nelson named his project after the poem by S. T. Coleridge “Kubla Khan” (or, “A Vision in a Dream”STC) , to suggest “the magic place of literary memory where nothing is forgotten.”XU The reason that “nothing is forgotten” in the Xanadu system is that, unlike the Web, it has no concept of deletion. Once a document has been published in the system, it will exist there forever. The original document remains the same except for the fact that a newer version can be created, “which would have references to the original version(s).”VB
Xanadu revolved around a concept of “transclusion,” which emphasized the reuse, inter-comparison and understanding of materials in different media. “Transcluded data is not copied from one object to another, but merely pointed at and brought when necessary from the original.”TN1 Thus, “electronic publication within the Xanadu system includes an implicit granting of the right to reference (or re-publish) within the Xanadu system.”CS
Xanadu publishing was principally based on selling copyrighted materials. In order to make this possible, the system would guarantee that “the owner of any information be paid their chosen royalties on any portion of their documents, no matter how small, whenever and wherever they are used.”XU
For example, when a reader accessed a document that quoted another one, the system traced the quote to its origin the author of the source document automatically received royalties. This way, there was no set price for a publication; instead, the author would get paid on “per-access” basis.
History of the Xanadu System
In the period of 1960-1979, Ted Nelson had been working on various designs of hypertext software. In 1972 the program implementation ran in programming languages Algol and Fortran. In 1979 Nelson assembled a new team for his project to redesign the system, with whose help the design of a “universal networking server” for Xanadu was completed in 1981. In 1983 the Xanadu Operating Company, Inc. was formed to complete development of the 1981 design.XU
In 1988, the company was purchased by Autodesk (makers of AutoCAD), but in 1992 Autodesk “dropped” the project.TN2 The reason why Autodesk gave up Xanadu is unclear. Perhaps, it was due to the fact that despite the decades of research and development, the group never officially released a single product. Or, perhaps, the company management deemed that the sprint of the World-Wide Web made further development of the system unnecessary.
After Nelson reorganized his project in 1993, he was invited to work in Japan, where he was developing the Xanadu system in late nineteen nineties. “The nature and difference of my designs,” said Nelson, “has not been well understood in the American computer world, where ideas are reduced to slogans and sales ratings. My ideas have been much better understood abroad especially in Japan.”TN1
Unfortunately, the Xanadu system failed to materialize. Fortunately, the World-Wide Web gained traction as the the “universal interactive media.” Yet, its current design has certain problems.
Some Weaknesses of the Web
The Web began as a set of simple protocols and formats. As time passed, the Web “began to be used as a testbed for various sophisticated hypermedia and information retrieval concepts.”RCH Unfortunately, these concepts were quickly absorbed by the general Web community. “This means that experimental extensions of dubious use are now established parts of the Web.”RCH
Another flaw in the current structure of the Web is the presence of many hypertext links that point to no longer existent documents. These occur when authors rename or delete their works from the Web.RCH Since the system has no way of registering links to one’s document, an author can not notify his readers of the reorganization. The Xanadu system, on the other hand, does not have this problem since it does not allow users to delete documents from the system.
Conclusion: Success of the Web
What is the reason for the immense success of the Web? Perhaps, it can be explained by CERN’s attitude towards the development of the project. As soon as the basic outline of the Web was complete, CERN made the source code for its software publicly available.CERN2 CERN has been encouraging collaboration by academic and commercial parties since the onset of the project, and by doing so it got millions of people involved in the growth of the Web.
The system requirements for running a Web server are minimal, so even administrators with limited funds had a chance to become information providers. Because of the intuitive nature of hypertext, many inexperienced computer users were able to connect to the network. Furthermore, the simplicity of the HyperText Markup Language (HTML), used for creating interactive documents, allowed these users to contribute to the expanding database of documents on the Web. Also, the nature of the Web provided a way to interconnect computers running different operating systems, and display information created in a variety of existing media formats (see Figure 3).
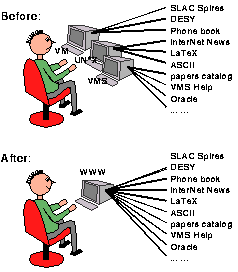
The possibilities for hypertext in the world-wide environment are endless. With the Web continuing to expand at an incredible rate, no one knows what awaits this universal information sharing platform as it permeates all aspects of our lives.
A Note About This Paper
I wrote this paper in April 1995 in an attempt to explore the origins of the World-Wide Web, which was beginning its explosive growth at that time. The paper has withstood the test of time well; referring to historical facts, it continues to be relevant today. I briefly edited this paper in 2005 then again in 2015 to update links in the References section and tweak some wording.
References
VB V. Balasubramanian, “The State of the Art Review on Hypermedia Issues And Applications,” December 1993. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.36.2631. February 2015.
CB Charles H. Buchholtz, “Eniac’s WWW Server,” a posting to USENET newsgroup upenn.seas.eniac.new on April 12, 1995.
CERN1 ” Joint World Wide Web Initiative.” URL: http://www.w3.org/Consortium/Prospectus/Hosts.html. January 2005.
CERN2 “The Policy of the WWW Project at CERN.” URL: http://www.w3.org/Policy.html. January 2005
STC Samuel Taylor Coleridge, “Kubla Khan,” 1798. URL: http://www.poetryfoundation.org/poem/173247. February 2015.
GL “Glossary.” URL: http://www.w3.org/History/1993/WWW/Conditions/Glossary.html. January 2005.
TN1 “Nelson Going To Japan, Will Design Media At New Hyperlab,” from The Ted Nelson News Letter, Number 3, October 1994. URL: http://www.aus.xanadu.com/itimes/999. 1995.
DH David Hirmes “Frequently Asked Questions (FAQ) File for alt.hypertext,” January 1993. URL: http://www.kevcom.com/words/ht93/hypertext.faq.txt. January 2005. The FAQ refers to the Vannevar Bush article titled “As We May Think,” which as published in the July 1945 issue of The Atlantic Monthly; it is available at http://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881.
KH Kevin Hughes “Entering the World-Wide Web: A Guide to Cyberspace,” Honolulu Community College, September 1993. URL: http://www.contra.org/docs/guide. January 2005.
JL Joe Levy, “The World in a Web,” The Guardian, page 19, November 11, 1993. URL: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.49.7130&rep=rep1&type=pdf. February 2015.
TN2 Ted Nelson, “The Story So Far,” from The Ted Nelson News Letter, Number 3, October 1994. URL: http://www.aus.xanadu.com/itimes/993. February 2015.
NS New Scientist Magazine, December 17, 1994 Issue. URL: http://www.newscientist.com/issue/1917. February 2015.
RCH Liam Relihan, Tony Cahill & Michael G. Hinchey, “Untangling the World-Wide Web.” URL: http://dl.acm.org/citation.cfm?id=192531. February 2015.
CS Craig Sanders, “Xanadu—More Than Just Electronic Publishing and Document Storage.” URL: http://xanadu.com.au/xanadu/desktop.html. January 2005.
BCG Tim Berners-Lee, Robert Cailliau, J.F. Groff & B.Pollermann, “World-Wide Web: An Information Infrastructure for High-Energy Physics,” presented at the Software Engineering, Artificial Intelligence and Expert Systems for High Energy and Nuclear Physics, La Londe-les-Maures, France, January 1992. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.38.1253. February 2015.
TC1 Tim Berners-Lee & Robert Caillian, “World-Wide Web: Proposal for HyperText,” CERN Memo, November 1990. URL: http://www.w3.org/hypertext/WWW/Proposal. January 2005.
TC2 Tim Berners-Lee & Robert Cailliau, “World-Wide Web,” presenting at the Computing in High Energy Physics conference in Annecy, France, September 23-17, 1992. URL: http://www.freehep.org/chep92www.pdf. January 2005.
XU “Xanadu FAQ.” URL: http://xanadu.com.au/xanadu/faq.html. January 2005.














![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


