
Designing a highly reliable small & medium business network
If you’ve ever been an IT manager for a small business network, you’re aware of one simple fact: small and medium business (SMB) networks are generally something of a mess. Typically, they’re organically grown and built off of consumer-class hardware. Network management tools are usually non-existent, documentation is erratic, and redundancy is totally absent. The end result is that the typical SMB network is a virtual fireball, with the network admin running around carrying a pail and trying to extinguish the fires.
What tends to happen, eventually, is that one of these outages becomes damaging enough to cause management to demand a better infrastructure. There’s always a catch, however, and in most cases it’s money. Luckily, you can build a highly reliable network without breaking the bank, as long as you focus on eliminating high-impact, single points of failure.
In this article, I’ll explain how to create a highly available SMB network. In order to be as vendor-neutral as possible, I will try to avoid specific technologies, and will instead lay out some goals, along with common methods for meeting those goals. For similar reasons, I will not detail exact costs, but where possible, I’ll give you relative costs. Finally, I won’t include virtualization options in this article, and will instead focus on standard client-server infrastructures. While virtualization can allow for very highly available infrastructures, a fully virtualized infrastructure is beyond the grasp of most small to medium sized businesses.
Client design: rapid recovery
Before discussing the best options for availability on the client side, we should point out one highly important fact: Client failures are not generally high-impact failures. One client machine failing will typically only affect one user. While there are occasions (such as the failure of a major executive’s system) that break this rule, in general, client redundancy is not worth the expense. Instead of redundancy, the focus for client systems should be on rapid recovery.
Enabling rapid recovery of client systems involves three major components: commodity hardware, network storage of user data, and disk imaging. Essentially, the goal is to be able to replace the user’s system as quickly as possible. If you use commodity hardware, it becomes easy to maintain shelf spares that you can quickly swap for a defective system in the case of hardware failure. For major software failures, maintaining an up-to-date base disk image allows you to rapidly redeploy a working image onto the machine. In both cases, however, user data must be housed on the network, or data loss will occur.
Advertisement
The details on how to implement this will be dependent on your chosen OS, but the basic principles are the same. Where possible, when making tradeoffs, try to choose the option that reduces downtime as much as you can. For example, to image a system you could use a basic image with just the OS, and use a software installation service to individually install applications once the machine is online. Alternately, you could use a complete image with the OS and all of the apps preinstalled. In general, the second option is going to be faster, but has the disadvantage of being harder to maintain. If reducing downtime is your primary goal, however, using complete disk images is the obvious choice.
Laptops, however, can complicate the client design. Since laptops are not always connected to the network, using entirely network-based data storage is not acceptable for these users. The solution, generally, is to use a caching mechanism. For example, on Windows systems, you can use offline files to handle the caching of raw data files, and allow roaming profiles to be cached to handle user profile issues.
Next, examine your cable plant. If you are installing new cable, it’s generally a good idea to pull double the number of cables for each drop. There are a few reasons for this. First, if you have some kind of major failure with a cable (rats chewing through insulation are not unheard of), you can quickly switch off to a different jack. Second, if at some point in the future you decide to use NIC teaming to increase the speed or reliability of the system’s network connection, you will have that option. Also, most of the cost of running cable is in labor, so it is generally very cheap to start with two cables for a drop, but very expensive to go back and add a second one later.
Switching design basics
On the switching side, your key considerations are:
- Whether or not to use a collapsed core
- Core redundancy and trunk redundancy
- Switch choices and load out
- Spanning Tree design
- L3 switching model
For the base design, for a network of this size, you are typically looking at a collapsed core design, similar to the one shown below. This means that all of the real switching complexity is concentrated at the core.
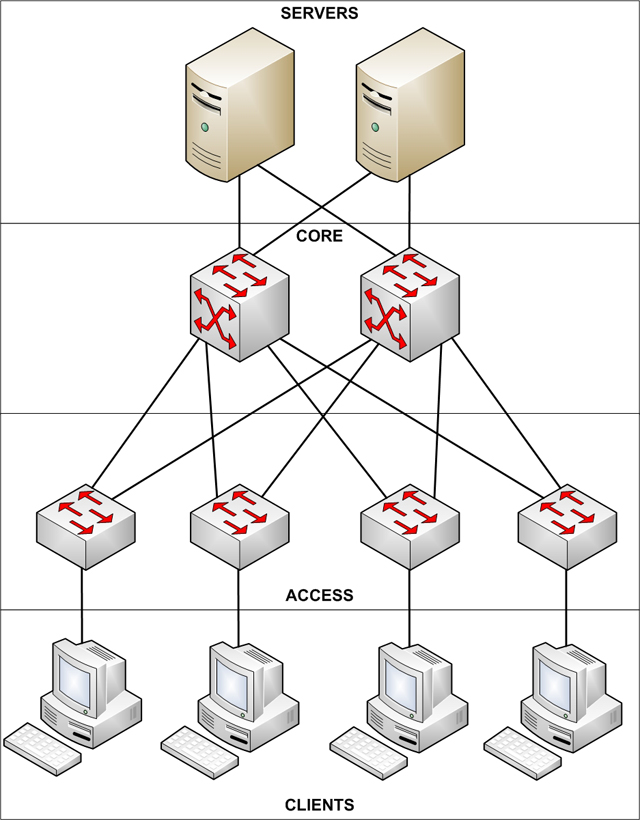
A collapsed core design














![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


