
Data Lake vs Data Warehouse for Enterprise Data Integration | BryteFlow
Mục Lục
Enterprise Data Lake vs Enterprise Data Warehouse, which one is right for you?
The enterprise data lake vs enterprise data warehouse conundrum is baffling many organizations. These days almost all large organizations are looking for real-time enterprise data integration to get the most from their data. Petabytes of data reside in legacy databases like SAP, Oracle, SQL Server, Postgres, and MySQL. Data that needs to be extracted, replicated, merged, transformed, and stored for analytics, ML and AI purposes. Organizations need an enterprise data solution that can deliver on data requirements and fit their budgets. Typically, enterprise data warehouses and enterprise data lakes are used by organizations to manage, store, and analyze their data effectively. Build a Data Lake or Data Warehouse on Snowflake
Enterprise data warehouses have been around longer than enterprise data lakes. They store structured data that is cleaned and organized for business analytics and can be accessed by reporting and BI tools. An enterprise data lake can store both- structured and unstructured data in the raw form, that can be processed when required for analytics. BryteFlow enables no-code, real-time data lakes using CDC on Amazon S3, ADLS Gen2 and Snowflake. It also builds real-time data warehouses on Amazon Redshift, Azure Synapse, SQL Server and Snowflake. Learn how BryteFlow works
Contents
What is an Enterprise Data Lake?
An enterprise data lake is a vast centralized data repository that can store all your data -structured and unstructured, with almost unlimited scalability. Earlier organizations had to be selective about which data to store since data aggregation and storage was expensive and only very essential data was stored. New data technologies and cloud platforms like data lakes have radically changed how organizations store and use data, they can literally store all their data in low-cost enterprise data lakes and query data as needed. Integrated and unified enterprise data lakes can have vast amounts of data coming in from multiple sources, and this data can be stored, structured, and analyzed to drive effective business decisions. Build an Amazon S3 Data Lake
Enterprise data lakes can store all types of data
Enterprise data lakes are flexible and can store all kinds of data including structured, unstructured, and semi-structured. Structured and semi-structured data includes JSON text, CSV files, website logs, or even telemetry data coming from equipment and wearable devices. An enterprise data lake supports storage of IoT type data for real-time analysis. Unstructured data could include photos, audio recordings and email files. Raw data in an enterprise data lake lends itself easily to the creation of Machine Learning (ML) models – access to huge amounts of data is a prerequisite in training ML models and making effective predictions from data for customer retention, equipment maintenance, managing inventory and more. Enterprise data lakes can be built on multiple cloud-based platforms like Amazon S3, Azure Synapse, Snowflake, Google Big Query etc. Build an Azure Data Lake on ADLS Gen2
What is an Enterprise Data Warehouse (EDW)?
An enterprise data warehouse or EDW as it is popularly known, is a centralized repository of data where organizations store data from operational business systems and other sources in a structured format. Data sources include Online Transaction Processing (OLTP) databases, Enterprise Resource Planning (ERP) and Customer Relationship Management (CRM) databases. ELT in Data Warehouse
The concept of the enterprise data warehouse is to aggregate data into one location where it can be merged and analyzed to enable organizations to derive effective business insights and strategize accordingly. For e.g., a retailer would find it useful to query the orders, products, and past sales figures to decide which products to push in the next season. Build a Data Lakehouse on Amazon S3 without Hudi or Delta Lake
Enterprise Data Warehouses: Traditional and Cloud
Traditional enterprise data warehouses were deployed on-premise but increasingly they are being nudged out by cloud enterprise data warehouses that offer more flexibility, scalability, and better economics. However, they both have a SQL interface to integrate with BI tools and are optimized to support structured data. 6 reasons to automate your Data Pipeline
Extract Transform Load to the Enterprise Data Warehouse
Extract Transform Load (ETL) is the process by which data is extracted from the sources and mapped from the sources to the tables at destination in the enterprise data warehouse. The data is transformed to a format that can be queried in the enterprise data warehouse to allow for reporting and BI analytics. Learn about BryteFlow’s AWS ETL
Data Warehouses can be of different types
Data warehouses include the enterprise data warehouse (EDW) that drives decision support for the complete organization, an Operational Data Store (ODS) that might have specific functions like reporting employee data or sales data. Then there are Data Marts where users can have smaller sections of data that are specific to their requirements. Running queries on the smaller Data Marts is much faster than querying the entire data of the data warehouse. Data Migration 101
Cloud Data Warehouses
Traditional data warehouses like Teradata still exist but organizations are increasingly adopting the cloud data warehouses like Snowflake, Amazon Redshift and Azure Synapse to replace or complement on-premise enterprise data warehouses. With enterprise cloud data warehouses users receive many benefits:
- They do not need to buy or maintain expensive hardware for the enterprise data warehouse.
- Implementation in the enterprise data warehouse is faster with almost unlimited scalability. Data Migration 101 (Process, Strategies and Tools)
- The cloud is elastic and flexible allowing organizations to benefit from Massively Parallel Processing (MPP) workloads, making it faster and much more cost-effective.
- ETL workflows are also faster, cloud databases may enable column-oriented queries with OLAP tools on the database, reducing the requirement of preparing data in advance, which is typical of traditional data warehouses.
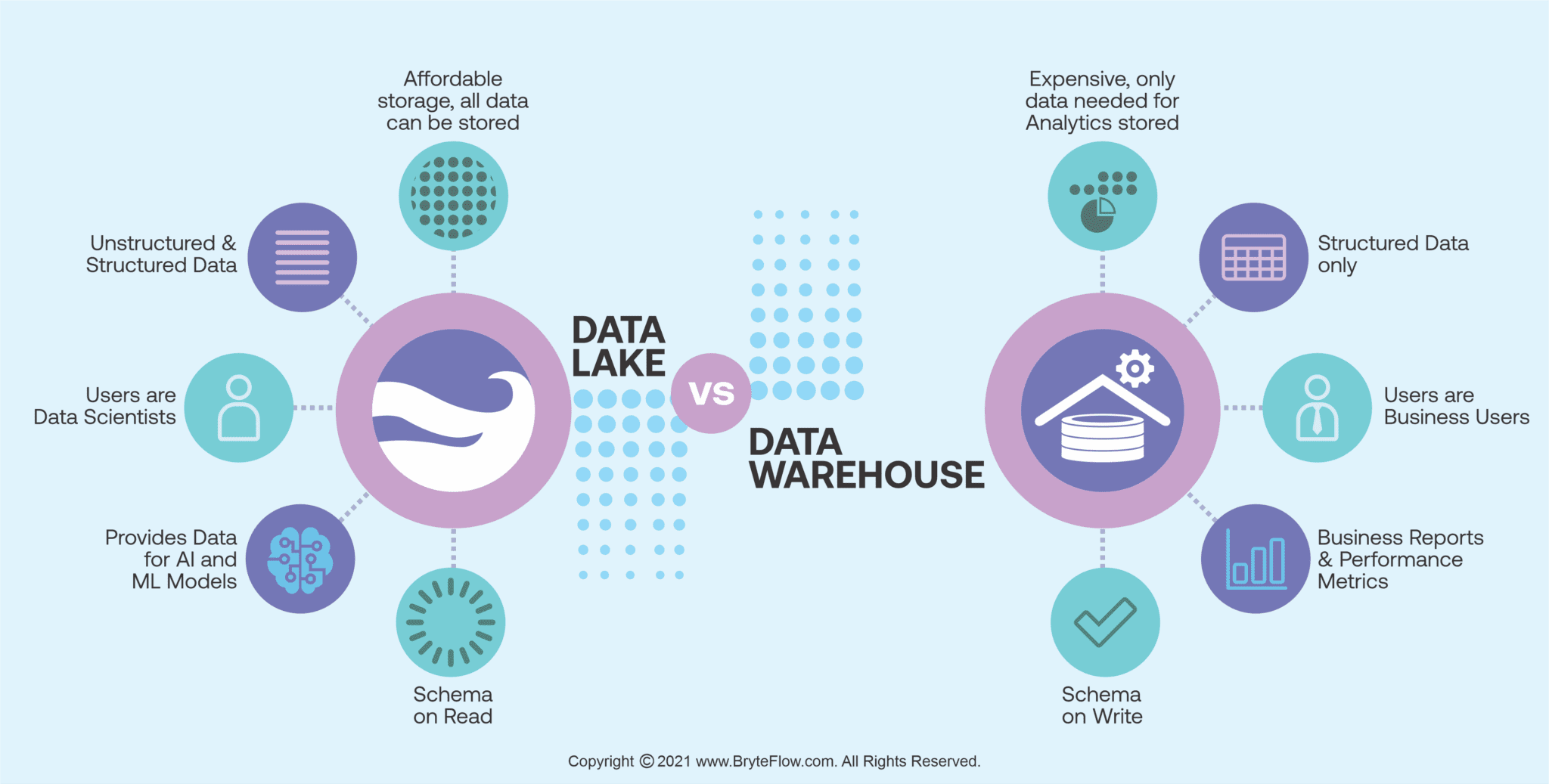
Enterprise Data Lake vs Enterprise Data Warehouse: Differences at a glance
Feature
Enterprise Data Lake
Enterprise Data Warehouse
Types of Data
Holds all types of data-raw, structured, and semi-structured
Holds only structured data
Data Storage & Cost
Petabytes of data can be stored for very long periods since storage costs are low
Usually, only data required for analytics is kept, since data warehouse costs are high
Data Processing
Uses the ELT (Extract, Load Transform) process
Uses ETL (Extract, Transform, Load) process
Schema
Schema is On-Read and applied later, only when data is required for analytics
Schema is On-Write and needs to be pre-defined before data is loaded
Users
Users are usually data professionals like data scientists who are familiar with deep analytics concepts like predictive modeling and statistical analysis
Users are usually business users since data is structured and can be easily used and understood by them
Queries
Querying is more ad hoc; users can access data before the data is transformed but this needs a level of technical knowledge
Querying consists of pre-defined questions for pre-defined data types
Tasks of Data
Users can query data in new and different ways. Data can be used for Machine Learning and AI models
Data is usually used by operations executives to generate business reports and performance metrics
Elaborating on the Enterprise Data Lake and Enterprise Data Warehouse Differences
Enterprise data lakes are data agnostic while enterprise data warehouses need structured data
Data Lakes can store data in its raw form from multiple sources. Data can be structured or unstructured. Users access data on a schema-on-read basis so data is usually unstructured, it will not be understood by a normal business user and needs organization with metadata. Metadata is a referral and tagging system that helps people search for different types of data. A data scientist would be able to use the data because of his special skillsets. In the case of the enterprise data warehouse, data is always structured and organized and can be queried by business users like marketing teams, BI experts, and data analysts. Build an S3 Data Lake in Minutes (with videos)
Schema-on-Read vs Schema-on-Write for data access
A schema is intended to bring organization and structure to a database and ensures tables, descriptions, IDs use a common language that can be understood easily by all users. This is a framework or pattern of the contents of the data and how it will relate to other tables or models. It is a language regulated by the DBMS of the specific database. A database schema includes important data, correct data formatting, unique keys for entries and objects, and names and date type for each column. Data Integration on Amazon S3 Data Lake
With an enterprise data lake, users can apply the schema only when they need to read the data (schema-on-read). This is especially useful for businesses needing to access new data sources frequently. Rather than defining a new schema every time, they can define it only when the data is required, saving a great amount of time and effort. Why Machine Learning models need Schema on Read
Enterprise data warehouse users on the other hand need to use schema-on-write. They need to define the schema before loading data to the enterprise data warehouse. This can take considerable effort and time and is suitable for organizations that must process the same type of data repetitively.
Enterprise Data Lakes typically store more data than Enterprise Data Warehouses
In an enterprise data lake, storage and compute are decoupled and can scale independently. Storage cost is much cheaper than an enterprise data warehouse. Businesses can store all their data on the data lake and only pay for processing of the data required, keeping compute costs low. Enterprise data lakes are therefore much larger in capacity than an enterprise data warehouse. In on-premise data warehouses, storage and compute are closely coupled. They scale up together thereby increasing costs. How to reduce costs on Snowflake by 30%
ELT for Enterprise Data Lake vs ETL for Enterprise Data Warehouse
In an enterprise data lake data is extracted from sources, loaded, and then transformed (ELT) while in an enterprise data warehouse, data is extracted, transformed, and then loaded. ELT loads data directly to the destination in a steady, real-time stream, while ETL loads data from the source to the staging area and then to the destination, usually in batches. However, BryteFlow provides real-time replication using Change Data Capture for both, ensuring fast, real-time replication of data. Learn about AWS ETL by BryteFlow
Enterprise Data Lakes are used for ad hoc queries while Enterprise Data Warehouses support complex querying
An enterprise data lake being the repository of all kinds of unstructured data requires the efforts of data scientists and experts to sort data for queries. This querying is more ad hoc (for e.g., using AWS Athena to query data on an S3 data lake) and more for analytical experiments for predictive analytics. Enterprise data warehouses yield results that are more comprehensible and can be easily understood through reporting dashboards and BI tools – users can easily gain insights from analytics to aid business decisions.
Data in an enterprise data warehouse has a definite objective while data in an enterprise data lake is more random
Raw data is stored in the enterprise data lake whether it is singled out for use or not, an enterprise data warehouse has only processed data that is intended for a particular purpose.
Data is stored in an enterprise data lake for long durations as compared to an enterprise data warehouse
Storage in an enterprise data lake is usually cheap, organizations can store their data for very long durations, and they can refer to it whenever the need arises. Data in enterprise data warehouses is usually retained for BI analytics and archived in a data lake or deleted when the purpose is served, since data storage in an enterprise data warehouse can be very expensive. Create an S3 Data Lake in Minutes with BryteFlow
Enterprise data lakes have agility and flexibility built in while enterprise data warehouses are more structured
Changes can be made to an enterprise data lake with relative ease since it does not have many limitations, the architecture does not have a defined structure, and it can also be accessed more easily. By comparison, the enterprise data warehouse is very structured and will take considerable effort to alter or restructure. An enterprise data lake can be easily scaled up for adding sources and processing larger volumes -this is partly the reason why ad hoc queries and data experimentation is much easier on a data lake. The enterprise data warehouse however, by dint of its rigid structure lends itself well for complex, repetitive tasks and can be used by business users who can make sense of the data easily. Alternately, one may need a data scientist or developer to query an enterprise data lake due to its free-wheeling nature and the sheer volumes of data contained in it.

Enterprise Data Lake or Enterprise Data Warehouse – how to decide
Enterprise data lakes are becoming more sophisticated by the day and enable users to do much more than old first-generation data lakes. New enterprise data lakes like the ones on Snowflake are blurring the distinction between a data lake and data warehouse with built-in scale, flexibility, and cost-effectiveness. However, organizations have older enterprise data warehouses with large, invested capital that will not be jettisoned anytime soon. If you are just getting into enterprise data integration, here are a few pointers to guide you:
When an Enterprise Data Lake makes sense:
- Data that needs to be aggregated is not known in advance
- There are huge datasets that may be growing, and storage costs may be an issue. Learn about Bulk Loading Data to Cloud Data Warehouses
- Data is collected from many sources and has different formats that do not adhere to a tabular or relational model
- Complete, raw datasets are needed for objectives like data exploration, predictive analytics, and machine learning
- How data elements relate with each other is not yet known
When an Enterprise Data Warehouse is preferable:
- Organizations know which data needs to be stored and are so familiar with it, that they can delete redundant data or make copies easily
- Data formats do not change and are not anticipated to change in the future.
- The purpose of the data is generation of typical business reports and fast querying is needed
- Data is precise and carefully selected
- Data needs to be compliant with regulatory or business requirements and needs special handling for auditing or security purposes
Enterprise Data Lake and Enterprise Data Warehouse Use Case Examples
Enterprise Data Lake Use Cases include:
Mining : In the mining industry, analyzing seismic data to optimize drilling operations, gathering data from automated loading systems to improve logistical efficiency, and analyzing time series IoT data for data patterns that can be analyzed for prolonging life of digitally operated machinery, are just a few use cases for data in the enterprise data lake.
Healthcare : The healthcare industry throws off a lot of data in multiple formats. Data from EHR/EMR systems, datasets and programs from clinical trials, genomic research, patient reported data, exercise, or diet data from smart devices, can all be aggregated in the enterprise data lake. This data can be analyzed to predict healthcare outcomes, examine promising treatments, disease probability etc.
Power & Energy : Power utilities can use predictive analytics from customer data including consumption patterns, data from IoT sensors and devices, billing data and customer feedback to present customized personalized offerings for customers and reduce customer churn.
Enrterprise Data Warehouse Use Cases include:
Retail : In the retail industry, a lot of people need access to data for BI, for e.g., collating and analyzing sales reports by store, determine ranking of SKUs by using sales margins and inventory turnover. Determining high priority customers by way of sales is another application of data in the enterprise data warehouse.
Financial services : In financial services for e.g. mutual funds, organizations can run periodic reports about the performance of their funds based on performance, growth of assets under management, NAV etc.
Hospitality : Hotel chains can examine the profitability of their hotels at various locations with regular dashboard reports of occupancy rates, room rates, vacation sales, etc. for revenue management and pricing strategy. They can benchmark against competitors and analyze customer profiles to create targeted new offers.
It doesn’t have to be Enterprise Data Lake vs Enterprise Date Warehouse – a hybrid approach is ideal
Using an enterprise data warehouse and an enterprise data lake in tandem can prove very rewarding. It doesn’t have to be a case of data lake vs data warehouse – the advantages of implementing an enterprise data lake alongside your enterprise data warehouse are enormous:
You can save on storage costs by storing all your data in the enterprise data lake and only loading data needed for analytics to your enterprise data warehouse.
The enterprise data lake can be used as a staging area to load and transform data before it is loaded to the enterprise data warehouse. This will make more resources available on your data warehouse for analytics and make queries run much faster. This distributed data architecture can lower your costs considerably since compute on the enterprise data warehouse can be expensive.
For simple ad hoc queries you can query the data on the enterprise data lake itself -this saves on time since cleansing and preparation of data is not required – you can directly get to the task at hand.
You can load all types of data to your enterprise data lake and use it as a data repository that users can access when needed. Data that is not being used can also be shifted to the data lake from the enterprise data warehouse.
The AWS Enterprise Data Lake is an example
A case in point is an AWS enterprise data lake, you can store data on S3 in structured and unstructured formats and query it, using the analytic capabilities of Redshift, using its Spectrum feature. Redshift Spectrum can seamlessly scale up to handle volumes of data and return results fast while the Redshift data warehouse does not need to store the data on its disks.
Data Lakehouse Option
A Data Lakehouse is another data repository concept that is trending recently. In simplest terms, a data lakehouse is what you get when you combine the data lake and data warehouse. The data lakehouse provides the advantages of both, by enabling data processing on top of the data lake rather than loading the data to the data warehouse for BI or analytics. With a data lakehouse, storage costs are cheap, data quality is improved, and redundancy is removed. An ETL pipeline connects the raw data lake layer to the transformed, integrated data warehouse layer.
Create a Data Lakehouse on Amazon 3
Data Lakehouse Advantages
- The data lakehouse allows for concurrent reading and writing of data with multiple data pipelines.
- Transactional data can be written to the data lake but easily accessed in the data warehouse, enabling significant cost savings, especially when the transactional data volume and velocity is high
- Data lakehouses allow for the use of BI tools directly on data. You don’t have to store multiple copies of data in the data lake and data warehouse. This reduces latency and lowers costs. Data Lakehouse on Amazon S3
- With a data lakehouse there is only one data source and it is used by both- data scientists and business analysts for BI. The data has already been cleansed and prepared, making for faster analytics and is more recent than data in a data warehouse.
- Having a data lakehouse means you don’t have to transfer data between tools so the hassle of data access control and encryption on multiple platforms is avoided, and data governance can be done from a single point. The data is a single source of truth which makes for better data quality and data governance.
- The data lakehouse can store data in many formats including files, video, audio, and system logs. For queries, data is transformed into formats such as ORC, Avro and Parquet that can compress data and can be split across multiple nodes or disks to be processed in parallel to speed up queries.
Data Lakehouse Enabling Tools
Data Lakehouse enabling tools can enable building the Data lakehouse seamlessly. These can be commercial or open source like Apache Hudi, Delta Lake etc. With BryteFlow however, you don’t need any third-party tool like Apache Hudi etc. BryteFlow builds the data lakehouse automatically while ingesting the data in near real-time. It performs upserts on updated or deleted data automatically and then enables seamless integration with Amazon Athena and AWS Glue Data Catalog in the S3 data lake and Azure Synapse on an ADLS Gen2 data lake, with easy configuration of file formats and compression e.g. Parquet-snappy so you can use your data lake as a data lakehouse. GoldenGate CDC and a better alternative
Enterprise Data Lake /Enterprise Data Warehouse Automation with BryteFlow
BryteFlow is an ETL tool that replicates your data from multiple sources in real-time, providing enterprise data lake / enterprise data warehouse automation. BryteFlow replication uses Change Data Capture to sync data with source and capture every change. BryteFlow offers no-code, automated data replication and seamless, automated data reconciliation to validate data completeness to create real-time enterprise data warehouses and enterprise data lakes. It democratizes data and is a self-service tool that can be used by ordinary business users and data technologists alike. With an easy point-and-click interface, it removes the effort, time, and cost of manual coding. It delivers ready-for-analytics data to your enterprise data lake or enterprise data warehouse in real-time, superfast. Get a FREE Trial
Learn how BryteFlow works














![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


