
Six Types of Neural Networks You Need to Know About
Mục Lục
An Introduction to the Most Common Neural Networks
Neural Nets have become pretty popular today, but there remains a dearth of understanding about them. For one, we’ve seen a lot of people not being able to recognize the various types of neural networks and the problems they solve, let alone distinguish between each of them. And second, which is somehow even worse, is when people indiscriminately use the words “Deep Learning” when talking about any neural network without breaking down the differences.
In this post, we will talk about the most popular neural network architectures that everyone should be familiar with when working in AI research.
1. Feed-Forward Neural Network
This is the most basic type of neural network that came about in large part to technological advancements which allowed us to add many more hidden layers without worrying too much about computational time. It also became popular thanks to the discovery of the backpropagation algorithm by Geoff Hinton in 1990.
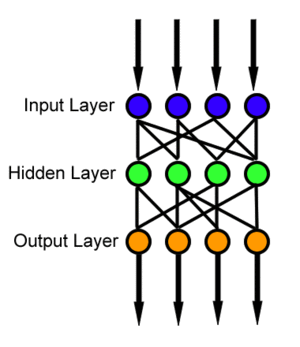
Source: Wikipedia
This type of neural network essentially consists of an input layer, multiple hidden layers and an output layer. There is no loop and information only flows forward. Feed-forward neural networks are generally suited for supervised learning with numerical data, though it has its disadvantages too:
1) it cannot be used with sequential data;
2) it doesn’t work too well with image data as the performance of this model is heavily reliant on features, and finding the features for an image or text data manually is a pretty difficult exercise on its own.
This brings us to the next two classes of neural networks: Convolutional Neural Networks and Recurrent Neural Networks.
2. Convolutional Neural Networks (CNN)
There are a lot of algorithms that people used for image classification before CNNs became popular. People used to create features from images and then feed those features into some classification algorithm like SVM. Some algorithm also used the pixel level values of images as a feature vector too. To give an example, you could train an SVM with 784 features where each feature is the pixel value for a 28×28 image.
So why CNNs and why do they work so much better?
CNNs can be thought of as automatic feature extractors from the image. While if I use an algorithm with pixel vector I lose a lot of spatial interaction between pixels, a CNN effectively uses adjacent pixel information to effectively downsample the image first by convolution and then uses a prediction layer at the end.
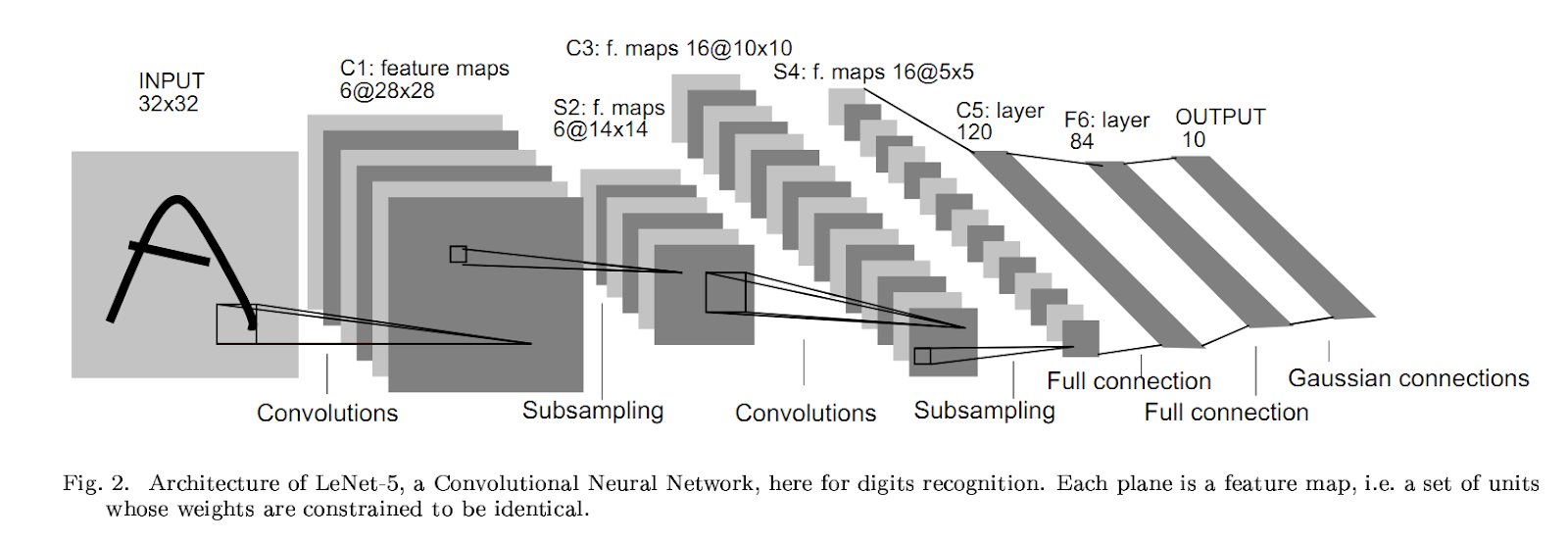
This concept was first presented by Yann le cun in 1998 for digit classification where he used a single convolution layer to predict digits. It was later popularized by Alexnet in 2012 which used multiple convolution layers to achieve state of the art on Imagenet. Thus making them an algorithm of choice for image classification challenges henceforth.
Over time various advancements have been achieved in this particular area where researchers have come up with various architectures for CNN’s like VGG, Resnet, Inception, Xception etc. which have continually moved the state of the art for image classification.
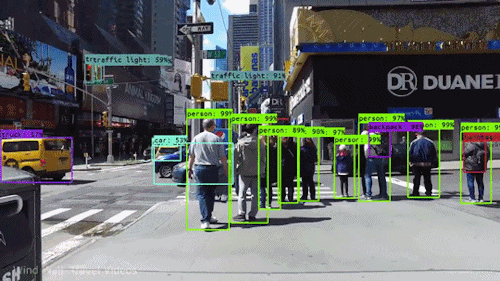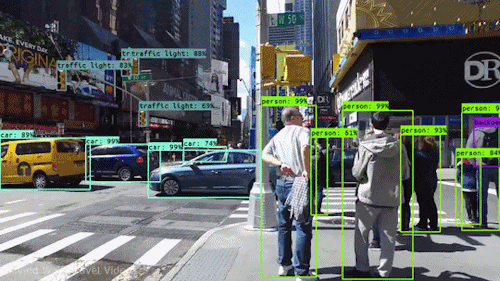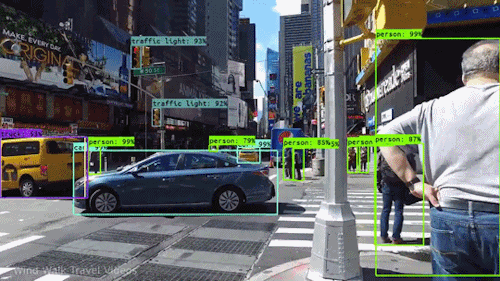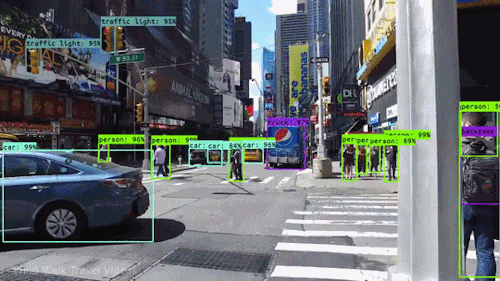
In contrast, CNN’s are also used for Object Detection which can be a problem because apart from classifying images we also want to detect the bounding boxes around various objects in the image. In the past researchers have come up with many architectures like YOLO, RetinaNet, Faster RCNN etc to solve the object detection problem all of which use CNNs as part of their architectures.
Here are a few articles you might want to look at:
3. Recurrent Neural Networks (LSTM/GRU/Attention)
What CNN means for images, Recurrent Neural Networks are meant for text. RNNs can help us learn the sequential structure of text where each word is dependent on the previous word, or a word in the previous sentence.
For a simple explanation of an RNN, think of an RNN cell as a black box taking as input a hidden state (a vector) and a word vector and giving out an output vector and the next hidden state. This box has some weights which need to be tuned using backpropagation of the losses. Also, the same cell is applied to all the words so that the weights are shared across the words in the sentence. This phenomenon is called weight-sharing.
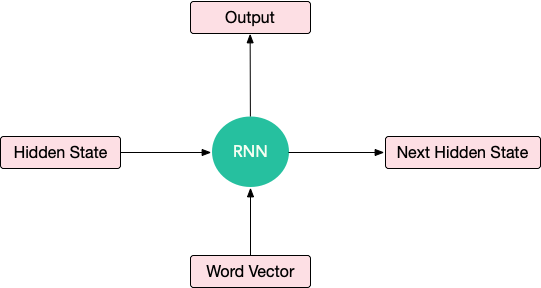
Hidden state, Word vector ->(RNN Cell) -> Output Vector , Next Hidden state
Below is the expanded version of the same RNN cell where each RNN cell runs on each word token and passes a hidden state to the next cell. For a sequence of length 4 like “the quick brown fox”, The RNN cell finally gives 4 output vectors, which can be concatenated and then used as part of a dense feedforward architecture like below to solve the final task Language Modeling or classification task:
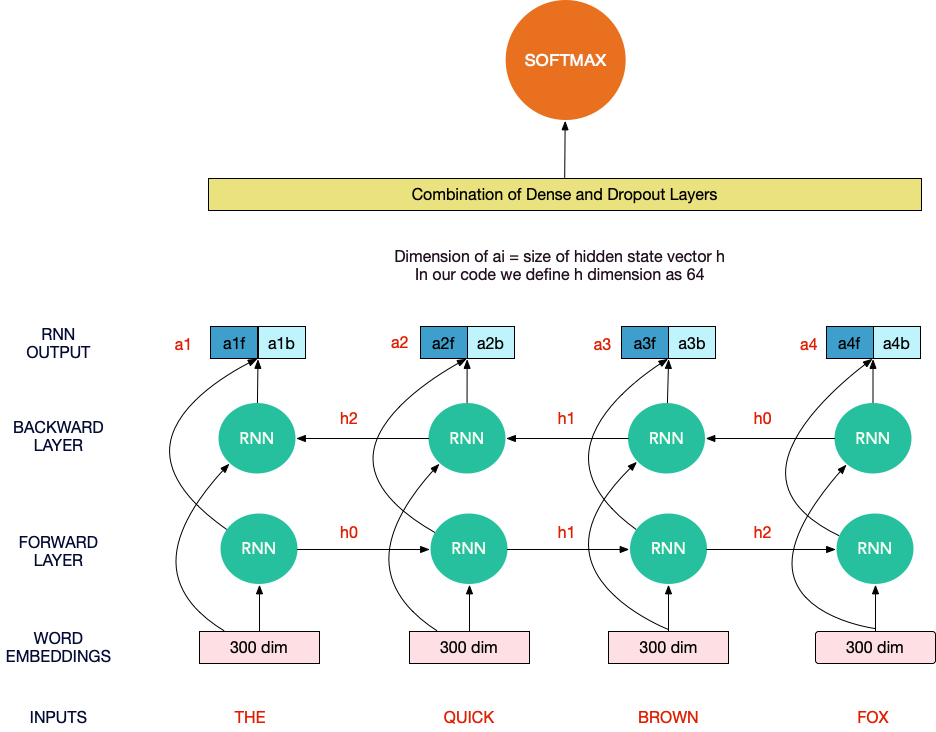
Long Short Term Memory networks (LSTM) and Gated Recurrent Units (GRU) are a subclass of RNN, specialized in remembering information for extended periods (also known as Vanishing Gradient Problem) by introducing various gates which regulate the cell state by adding or removing information from it.
From a very high point, you can understand LSTM/GRU as a play on RNN cells to learn long term dependencies. RNNs/LSTM/GRU have been predominantly used for various Language modeling tasks where the objective is to predict the next word given a stream of input Word or for tasks which have a sequential pattern to them. If you want to learn how to use RNN for Text Classification tasks, take a look at this post.
Next thing we should mention are attention-based models, but let’s only talk about the intuition here as diving deep into those can get pretty technical (if interested, you can look at this post). In the past, conventional methods like TFIDF/CountVectorizer etc., were used to find features from the text by doing a keyword extraction. Some words are more helpful in determining the category of text than others. However, in this method we sort of lost the sequential structure of the text. With LSTM and deep learning methods, we can take care of the sequence structure but we lose the ability to give higher weight to more important words. Can we have the best of both worlds? The answer is Yes. Actually, Attention is all you need. In the author’s words:
Not all words contribute equally to the representation of the sentence’s meaning. Hence, we introduce attention mechanism to extract such words that are important to the meaning of the sentence and aggregate the representation of those informative words to form a sentence vector
4. Transformers
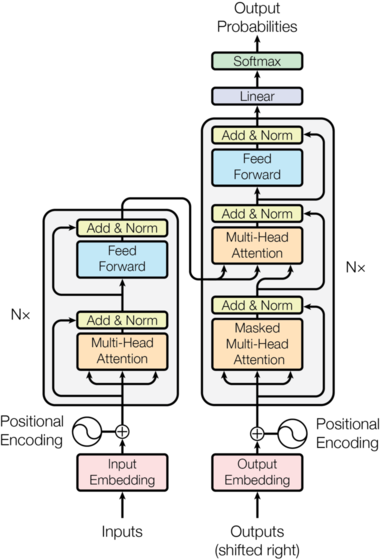
Source
Transformers have become the defacto standard for any Natural Language Processing (NLP) task, and the recent introduction of the GPT-3 transformer is the biggest yet.
In the past, the LSTM and GRU architecture, along with the attention mechanism, used to be the State-of-the-Art approach for language modeling problems and translation systems. The main problem with these architectures is that they are recurrent in nature, and the runtime increases as the sequence length increases. That is, these architectures take a sentence and process each word in a sequential way, so when the sentence length increases so does the whole runtime.
Transformer, a model architecture first explained in the paper Attention is all you need, lets go of this recurrence and instead relies entirely on an attention mechanism to draw global dependencies between input and output. And that makes it fast, more accurate and the architecture of choice to solve various problems in the NLP domain. If you want to know more about transformers, take a look at the following two posts:
5. Generative Adversarial Networks (GAN)

Source: All of them are fake
People in data science have seen a lot of AI-generated people in recent times, whether it be in papers, blogs, or videos. We’ve reached a stage where it’s becoming increasingly difficult to distinguish between actual human faces and faces generated by artificial intelligence. And all of this is made possible through GANs. GANs will most likely change the way we generate video games and special effects. Using this approach, you can create realistic textures or characters on demand, opening up a world of possibilities.
GANs typically employ two dueling neural networks to train a computer to learn the nature of a dataset well enough to generate convincing fakes. One of these neural networks generates fakes (the generator), and the other tries to classify which images are fake (the discriminator). These networks improve over time by competing against each other.
Perhaps it’s best to imagine the generator as a robber and the discriminator as a police officer. The more the robber steals, the better he gets at stealing things. At the same time, the police officer also gets better at catching the thief.
The losses in these neural networks are primarily a function of how the other network performs:
- Discriminator network loss is a function of generator network quality: Loss is high for the discriminator if it gets fooled by the generator’s fake images.
- Generator network loss is a function of discriminator network quality: Loss is high if the generator is not able to fool the discriminator.
In the training phase, we train our discriminator and generator networks sequentially, intending to improve performance for both. The end goal is to end up with weights that help the generator to create realistic-looking images. In the end, we’ll use the generator neural network to generate high-quality fake images from random noise.
If you want to learn more about them here is another post:
6. Autoencoders
Autoencoders are deep learning functions which approximate a mapping from X to X, i.e. input=output. They first compress the input features into a lower-dimensional representation and then reconstruct the output from this representation.
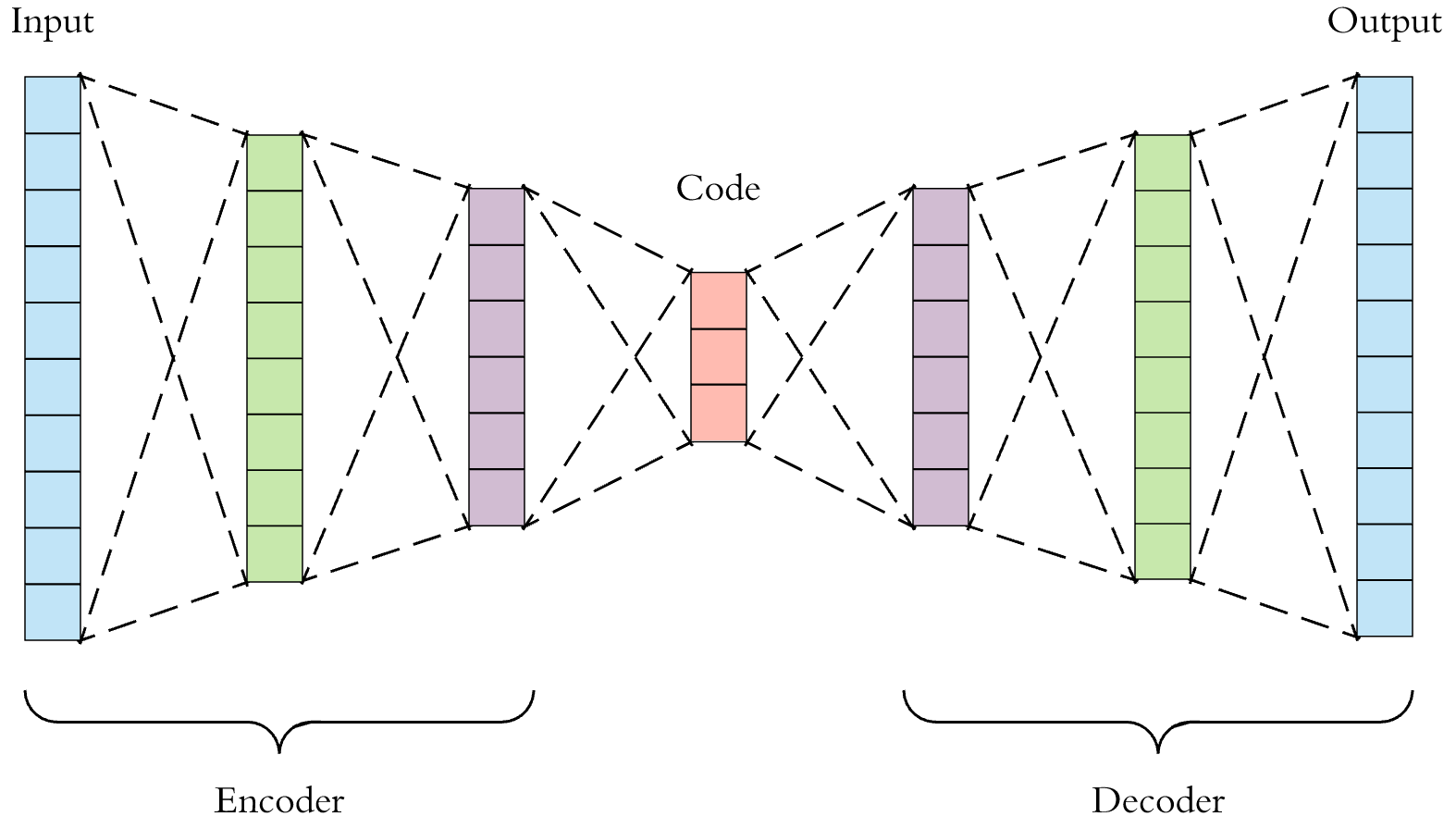
In a lot of places, this representation vector can be used as model features and thus they are used for dimensionality reduction.
Autoencoders are also used for Anomaly detection where we try to reconstruct our examples using our autoencoder and if the reconstruction loss is too high we can predict that the example is an anomaly.
Conclusion
Neural networks are essentially one of the greatest models ever invented and they generalize pretty well with most of the modeling use cases we can think of. Today, these different versions of neural networks are being used to solve various important problems in domains like healthcare, banking and the automotive industry, along with being used by big companies like Apple, Google and Facebook to provide recommendations and help with search queries. For example, Google used BERT which is a model based on Transformers to power its search queries.
If you want to know more about deep learning applications and use cases, take a look at the
Interested in a deep learning solution for AI research?
If you want to know more about deep learning applications and use cases, take a look at the Sequence Models course in the Deep Learning Specialization by Andrew Ng.
Get a workstation with up to 2x NVIDIA RTX 3070/3080/3090 starting at only $3,700













![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


