
Neural network verification: Where are we and where do we go from here?
Portions of this blog post are edited excerpts from the author’s book
Over the past decade, a number of hardware and software advances have conspired to thrust deep learning and neural networks to the forefront of computing. Deep learning has created a qualitative shift in our conception of what software is and what it can do: Every day we’re seeing new applications of deep learning, from medicine to astronomy to art, and it feels like we’re only scratching the surface of a universe of new possibilities.
At this point, it is more than safe to say that deep learning is here to stay, in one form or another. The line between software 1.0 (manually written code) and software 2.0 (learned neural networks) is getting fuzzier and fuzzier, and neural networks are participating in safety-critical, security-critical, and socially critical tasks. Think, for example, healthcare, self-driving cars, malware detection, etc. But neural networks are fragile and so we need to prove that they are well-behaved when applied in critical settings.
In this post, I will talk about the verification problem for neural networks and some of the prominent verification techniques that are being developed. I will also discuss the great challenges that our community is well positioned to address and some of the ideas that we can port from the machine-learning community.
Mục Lục
A little bit of history
For the programming languages community, statistical machine learning has always felt like a distant area of computing research, until of course very recently, thanks to the deep-learning revolution. Intriguingly, however, we can trace the genesis of the ideas of verification and neural networks all the way back to a two-year period of Alan Turing’s tragically short life.
In 1949, Turing wrote a little-known paper titled Checking a Large Routine. It was a truly forward-looking piece of work. In it, Turing asks: how can we prove that the programs we write do what they are supposed to do? Then, he proceeds to provide a proof of correctness of a program implementing the factorial function. Turing’s proof resembles what we now call Floyd-Hoare logic, with preconditions and postconditions annotating every program statement.
Just a year before Turing’s proof of correctness of factorial, in 1948, Turing wrote a perhaps more prophetic paper, Intelligent Machinery, in which he proposed unorganized machines. These machines, Turing argued, mimic the infant human cortex, and he showed how they can learn using what we now call a genetic algorithm. Unorganized machines are a very simple form of what we now know as neural networks.
What do we want to verify?
In Turing’s proof of correctness of his factorial program, Turing was concerned that we will be programming computers to perform mathematical operations, but we could be getting them wrong. So in his proof he showed that his implementation of factorial is indeed equivalent to the mathematical definition. This notion of correctness is known as functional correctness, meaning that a program is a faithful implementation of some mathematical function. Functional correctness is incredibly important in many settings—think of the disastrous effects of a buggy implementation of a cryptographic primitive or a BGP protocol (follow me on Instagram).
In the land of deep learning, proving functional correctness is an unrealistic task. What does it mean to correctly recognize cats in an image or correctly translate English to Hindi? We cannot mathematically define such tasks. The whole point of using deep learning to do tasks like translation or image recognition is because we cannot mathematically capture what exactly they entail, but we can demonstrate what we desire with a lot of examples.
So what now? Is verification out of the question for neural networks? No! While we cannot precisely capture what a neural network should do, we can often characterize some of its desirable or undesirable properties. Let’s look at three classes of such properties.
Robustness: The most-studied correctness property of neural networks is robustness, because it is generic in nature and neural networks are infamous for their fragility. Robustness means that small perturbations to inputs should not result in changes to the output of the neural network. For example, changing a small number of pixels in my photo should not make the network think that I am a chihuahua instead of a person, or deleting this paragraph from this blog post should not make a neural network think that this is a blog post about the Ming dynasty in the 15th century. Funny examples aside, lack of robustness can be a safety and security risk. Take, for instance, an autonomous vehicle following traffic signs using cameras. It has been shown that a light touch of vandalism to a stop sign can cause the vehicle to miss it, potentially causing an accident. Or consider the case of a neural network for detecting malware. We do not want a minor tweak to the malware’s binary to cause the detector to suddenly deem it safe to install.
Robustness is also closely related to notions of fairness in decision-making. Imagine a neural network that is used to estimate credit risk of various individuals for the purposes of issuing loans. You don’t want a small or meaningless change to someone’s financial record to cause their credit-risk prediction to swing wildly.
Safety: Safety is a broad class of correctness properties stipulating that a program should not get to a bad state. The definition of “bad” depends on the task at hand. Consider a neural-network-operated robot working in some kind of plant. We might be interested in ensuring that the robot does not exceed certain speed limits, to avoid endangering human workers, or that it does not go to a dangerous part of the plant, or mix certain chemicals that should not be mixed. Another well-studied example is a neural network implementing a collision avoidance system for aircrafts. One property of interest is that if an intruding aircraft is approaching from the left, the neural network should decide to turn the aircraft right.
Consistency: Neural networks learn about our world via examples, like images, videos, text, and various sensor data. As such, they may sometimes miss basic axioms, like physical laws, and assumptions about realistic scenarios. For instance, a neural network recognizing objects in an image and their relationships might say that object A is on top of object B, B is on top of C, and C is on top of A. But this cannot be! (At least not in the world as we know it.)
Or consider a neural network tracking players on the soccer field using a camera. It should not in one frame of video say that Ronaldo is on the right side of the pitch and then in the next frame say that Ronaldo is on the left side of the pitch—Ronaldo is fast, yes, but he has slowed down in the last couple of seasons.
How are we verifying neural networks?
There have been two primary classes of techniques for general neural network verification, and both stem from or relate to research in formal methods. (There are other specialized verification techniques that are heavily tied to specific forms of robustness; I will not discuss those.)
Constraint-based verification: These techniques take a neural network and a property of interest, and encode the verification problem as a set of constraints that can be solved by a Satisfiability Modulo Theories (SMT) solver or a Mixed Integer Linear Program (MILP) solver. Such techniques tend to be complete, in the sense that they can prove or disprove a property, returning a counterexample in the latter case. In the worst case, such techniques take exponential time in the size of the neural network, limiting their scalability.
Let’s look at a laughably simple neural network composed of a single neuron and written as a Python function:
def N(x,y): # linear transformation t = 3*x + 2*y # Rectified linear unit (ReLU) if (t is positive): r = t else: r = 0 return r
This network takes two inputs (real numbers) and returns one output (real number). Real-world neural networks are primarily composed of linear transformations and activation functions, like the ReLU (conditional) above. Suppose we want to prove the following property, which roughly resembles a robustness property:
if the inputs
xandyare between0and1, then the outputN(x,y)is greater than or equal to0.
First, we encode the neural network as a system of constraints, an SMT formula 
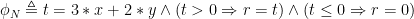
As you can see, the encoding resembles the code. The two implications (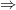
![\forall x,y \in [0,1] \ldotp \phi_N \Rightarrow r \geq 0](https://s0.wp.com/latex.php?latex=%5Cforall+x%2Cy+%5Cin+%5B0%2C1%5D+%5Cldotp+%5Cphi_N+%5CRightarrow+r+%5Cgeq+0&bg=ffffff&fg=000&s=0&c=20201002)
The way to read this is as follows: “If you execute N(x,y), where x and y are between 0 and 1, you get a return value r that is greater than or equal to 0”
The main challenge for the SMT solver is dealing with the ReLU piece, which makes the verification problem NP-hard. Intuitively, the conditional (non-linearity) introduced by the ReLU may force the SMT solver to explore both branches of the conditional. The set of possible paths to explore can grow exponentially with the number of available ReLUs. Not good! So researchers have come up with specialized decision procedures to natively handle ReLUs, but of course that can only take us so far with an NP-hard problem.
Abstraction-based verification: These techniques aim for scalability, avoiding the exponential explosion at the expense of completeness—sometimes they will just say “I don’t know!”. Specifically, these techniques employ abstract domains (see abstract interpretation) to evaluate the neural network on sets of inputs. The simplest abstract domain is the interval domain, where we treat every real-valued input of a neural network as an interval of real numbers instead. Interval arithmetic is pretty standard, and predates computer science. Since a neural network is just arithmetic operations, we can evaluate the neural network on intervals of inputs! This allows us to make general claims about the behavior of the network on infinite sets of inputs.
To apply abstraction-based verification to the example above, we start by assuming x and y are any values in the interval [0,1] and interpret the neural network using interval arithmetic. For instance, the first line t = 3*x + 2*y results in the conclusion that t is any value in the interval [0,5]. The lower bound 0 comes from the case where both x and y are 0; the upper bound 5 comes from the case where they are both 1. Evaluating the entire function, we conclude that r is in the interval [0,5], thus proving the property.
Interpreting the neural network over interval arithmetic is linear in the size of the neural network. Sadly, the approach loses precision, and therefore may produce larger intervals than actually conceivable. E.g., in our example, if the final interval for r is [-1,10], we won’t be able to prove the property that r is greater than or equal to 0.
Training + verification: It is important to point out that there’s a lot of interplay between training a neural network and verifying it. Usually, we don’t just get a neural network to verify, but we also train a neural network to be amenable to verification.
In constraint-based verification, the main factor limiting scalability is the number of ReLUs. So, if we can reduce the number of ReLUs, we scale verification farther. A key idea is biasing the training procedure to produce neural networks that are sparse with as few ReLUs as possible. Doing so produces encodings (like 
With abstraction-based verification, we tend to lose precision with every operation—some operations induce more precision loss than others. If we lose too much precision, the intervals become so large that we cannot prove properties of interest. A key idea is employing abstraction within the training procedure: instead of saying just optimizing the accuracy of the network on training data, we additionally optimize the precision of abstract interpretation of the neural network.
Where do we go from here?
At this point in time, the research community has developed a portfolio of powerful verification techniques. But they are limited in their applicability and scalability. Given that neural networks are constantly increasing in size and being applied to all sorts of novel problems, we have a lot of pressing challenges to tackle. I will now discuss some of these challenges and outline some interesting developments that we, as a programming languages community, can learn from.
Specification, specification, specification: One of the hardest problems in the field of verification—and the one that is least discussed—is how to actually come up with correctness properties, or specifications. For instance, innumerable papers have been written on robustness of neural networks. Robustness, at a high level, is very desirable. You expect an intelligent system to be robust in the face of silly transformations to its input. But how exactly do we define robustness? Much of the literature focuses on 
Therefore, coming up with the right properties to verify and enforce is a challenging, domain-dependent problem requiring a lot of careful thought. Research from programming languages and software engineering on specification mining comes to mind. Can we apply such ideas to mine desirable specifications of complex neural networks?
Scalability, scalability, scalability: Every year, state-of-the-art neural networks blow up in size, gaining more and more parameters. We’re talking about billions of parameters. There is no clear end in sight. This poses incredible challenges for verification. Constraint-based approaches are already not very scalable, and abstraction-based approaches tend to lose precision with more and more operations. So we need creative ways to make sure that verification technology keeps up with the parameter arms race.
One interesting line of work, called randomized smoothing, has shown that one can get high-probability correctness guarantees, at least for some robustness properties, by randomizing the input to a neural network. The cool thing about randomized smoothing is that it is a black-box technique—it doesn’t care about the internals of the neural network or how big the network is—making it very scalable. Improving randomized smoothing and applying it to richer properties is a promising strategy for tackling verification scalability. Perhaps it can even be applied to general verification problems beyond neural networks?
The stack is deep, deep, deep: Verification research has primarily focused on checking properties of neural networks in isolation. But neural networks are, almost always, a part of a bigger more complex system. For instance, a neural network in a self-driving car receives a video stream from multiple cameras and makes decisions on how to steer, speed up, or brake. These video streams run through layers of encoding, and the decisions made by the neural network go through actuators with their own control software and sensors. So, if one wants to claim any serious correctness property of a neural-network-driven car, one needs to look at all of the software components together, as a system. This makes the verification problem incredibly challenging for two reasons: (1) The size of the entire stack is clearly bigger than just the neural network, so scalability can be an issue. (2) Different components may require different verification techniques. Compositional-verification techniques are a natural next step to explore for reasoning about big software systems that employ neural networks.
Another issue with verification approaches is the lack of emphasis on the learning algorithms that produce neural networks. For example, training algorithms may themselves not be robust: a small corruption to the data may create vastly different neural networks. For instance, a number of papers have shown that poisoning the dataset through minimal manipulation can cause a neural network to pick up on spurious correlations that can be exploited by an attacker. Imagine a neural network that detects whether a piece of code is malware. This network can be trained using a dataset of malware and non-malware. By adding silly lines of code to some of the non-malware code in the dataset, like print("LOL"), we can force the neural network to learn a correlation between the existence of this print statement and the fact that a piece of code is not malware. This can then be exploited by an attacker. This idea is known as installing a backdoor in the neural network.
So it’s important to prove that our training algorithm is not susceptible to small perturbations in the input data. This is a challenging problem, but researchers have started to study it.
Environment, environment, environment: Often, neural networks are deployed in a dynamic setting, where the neural network interacts with the environment, e.g., a self-driving car. Proving correctness in dynamic settings is rather challenging. First, one has to understand the interaction between the neural network and the environment—the dynamics. This is typically hard to pin down precisely, as real-world physics may not be as clean as textbook formulas. Further, the world is uncertain, e.g., we have to somehow reason about crazy drivers on the road. Second, in such settings, one needs to verify that a neural-network-based controller maintains the system in a safe state (e.g., on the road, no crash, etc.). This requires an inductive proof, as one has to reason about arbitrarily many time steps of control. Third, sometimes the neural network is learning on-the-go, using reinforcement learning, where the neural network tries things to see how the environment responds, like a toddler stumbling around. So we have to ensure that the neural network does not do stupid things as it is learning.
Recently, there have been a number of approaches attempting to verify properties of neural networks in dynamic and reinforcement-learning settings, but a lot of work needs to be done. Connecting to the challenges above, state-of-the-art approaches do not scale to real-world systems (think Tesla’s autonomous driving system), rely on simple models of the environment, and do not handle the complexity of the software stack in which the neural network lives. Clearly, there’s lots of work to be done!
Thanks to Adrian Sampson for his careful reading and feedback.
Bio: Aws Albarghouthi is an associate professor at the University of Wisconsin–Madison. He works on program synthesis and verification.
Disclaimer: These posts are written by individual contributors to share their thoughts on the SIGPLAN blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGPLAN or its parent organization, ACM.

















![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


