
How To Create a Siamese Network With Keras to Compare Images
Last Updated on January 6, 2023 by Editorial Team
Last Updated on October 16, 2022 by Editorial Team
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
We are going to have a good time creating this Siamese Network. Maybe, this is a technique a little bit beyond the basics, but I can assure you that it’s useful and easy.
The whole code is available in Kaggle:
How to create a Siamese Network to compare images
Where you can execute the code, fork, and modify it if you want.
I have used the famous Dataset MNIST to train the system, with 42000 28×28 gray images of numbers handwritten. The model will try to identify whether two numbers are identical.
Mục Lục
Brief description of how works a Siamese Network.
It receives two inputs and produces two output vectors to calculate the euclidean distance between the vectors.

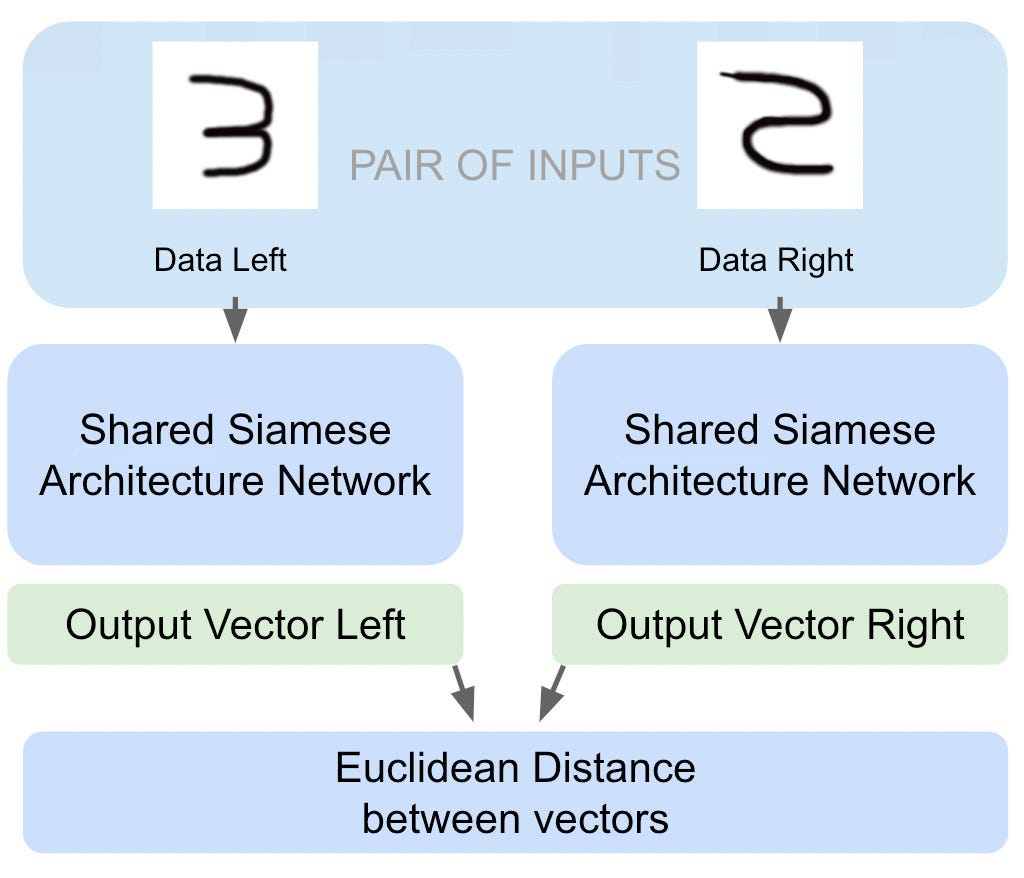 Image by Author
Image by Author
The output of the model is a number representing the differences between the inputs. We must decide the limit so that the images can be considered of the same type. As smaller the number returned by the model, the smaller the differences. If the model receives two identical images, the return value must be zero.
In which situations can a Siamese Network be useful?
Although they are widely used in fields such as facial recognition, Siamese networks are not limited to the field of images.
They are also very popular in NLP, where they can be used to identify duplicates, texts that deal with the same topic, or even identify if two texts are of the same style or author.
They can also be used to recognize Audio files, for example, to compare voices and know if they belong to the same person.
Siamese networks work whenever we want to compare two Items with each other, whatever their type. Are especially recommended when the training Dataset is limited. Since we can match the available Items differently, increasing the information that we can obtain from the data.
In the notebook, I have matched each item with another item on the list. But I could have matched each item more than once to different items in the dataset, creating as many input pairs as I wanted. Which would give us an impressive set of data. This possibility of combination allows us to have enough training data no matter how small the Dataset is.
Data Treatment.
To see the whole code, the best option is to have the Kaggle notebook open and follow along as you read.
Here I’m going to explain only the part where in which I create the pairs of data. The most specific part of data treatment to Siamese Networks.
This function iterates through each of the elements in the dataset and matches them with another element, resulting in several pairs equal to the number of elements in the dataset.
To ensure that there is a minimum number of elements with pairs of the same type, the min_equals parameter has been incorporated. The first pairs, until reaching min_equals, will be created with elements of the same type. The rest are matched randomly.
In the last lines, you can see how the pairs are created and stored in the pairs variable. Their labels are stored in the labels variable.
The data is transformed on return so that it can be treatable from the model.
Note this line at the beginning of the function: index = [np.where(y == i)[0] for i in range(10)]. It creates an array named index of 9 rows. Each row contains the positions of the numbers in the array of labels (y) that belong to the category indicated by the variable i.
That is, for index[0] we will have all the positions in the array y of the numbers with value 0. In Index[1], the positions of the value 1…
Creating the Siamese Model.
Before creating the model is necessary to do three functions. One is to calculate the Euclidean distance between the two output vectors. Another is to modify the shape of the output data. And a third, which is the loss function that is used to calculate the loss. Do not worry, it is a function, I would say, a standard for all Siamese models.
The loss function, contrastive_loss, is nested inside another function, contrastive_loss_with_margin, so that it allows us to pass a parameter to it. But it could have been ignored and always used the same value in the margin.
When building the model, the loss function is passed to the compile method, which takes care of passing the y_true and y_pred parameters so that the loss can be calculated at each step. We can’t pass any more parameters, so we nest the function. The compile method receives is the loss function that expects the input data y_true and y_pred.
The math formula, adapter to our variables, of the loss function, is:
Ytrue * Ypred² + (1 -Ytrue) * max(margin-Ypred, 0)²
Following the code, we see that in the variable square_pred we store the value of Ypred². In margin_square we store the value of max(margin-Ypred, 0)². From here, substituting the variables in the equation gives us the expression contained in the return line.
As I’m not going to enter into details about the maths involved, if you want more information, please refer to this articles:
Common part of the model.
This part is going to be executed for the two inputs, it is the common part of the model and receives a 28×28 image as input.
I have created a function containing the code for this part of the model. It is a very simple model, but we can build a more complicated one, as much as we consider necessary for our data. You can see that we have a Flatten layer followed by a mix of Dense and Dropout layers.
Note that the function returns a model with its input and output, not just a group of layers.
To this model, we will have to add the input layers and the output layer of the Siamese network.
Input and output layers of the Siamese model.
We have two input layers: input_l and input_r, both receive the base model and produce a Vector as output (vector_output_l, vector_output_r).
Each branch will receive a part of the data set that we have prepared.
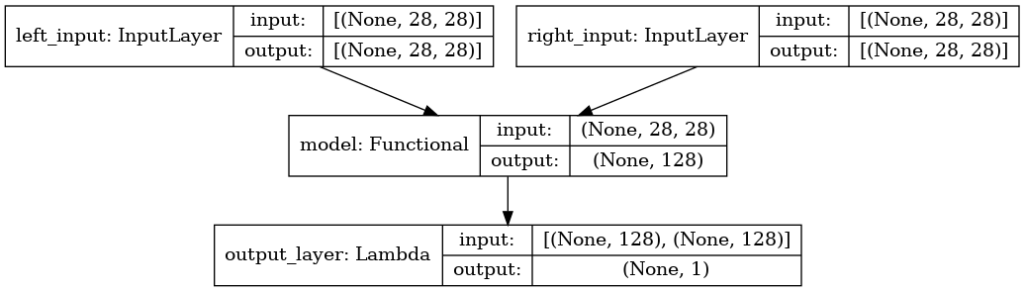
The output layer is created using a Lambda-type layer that calls the two functions created before. euclidean_distance that calculates the Euclidean distance, which will be the expected return. And eucl_dist_output_shape is the one that modifies the shape of the output and receives the two vectors.
As you can see in the Model creation, we pass the two input layers as inputs and the output layer as output. In the Siamese networks, we have two input layers and one output.
Time to train the model.
You can see in the fit call how we are passing the data prepared by the create_pairs function, on the left is the element [0], and on the right is the element [1]. And the same for the validations data.
Let’s see the results.


In the images, you can see 16 pairs of numbers chosen at random from the dataset, and there is not a single error.
If you try it in the Kaggle notebook, do as many runs as you want. Finding a bug is almost impossible. There is indeed a number that is very close to being misclassified: the pair of sixes in the second row gives us a score of 0.47…. a little bit more, and it would be classified as a different number.
If you prefer the numbers: Train Accuracy = 0.987075 Val accuracy = 0.968
But keep in mind that we have performed the training with a single data crossing! We could have crossed each number with two the same and two different ones, obtaining much more data for training. In these types of models, the inputs are pairs of data, so each pair is like a different input data.
Conclusions.
The result obtained with the Siamese network seems incredible to me. I have not worked too much with the data, I have not worried about the model, and the training has lasted just over two minutes. I haven’t used callback functions to touch the learning rate, and I haven’t even bothered to record the best model…. and still, the result is very good.
Siamese networks are very powerful for performing data pair checks. Or to check whether or not a piece of data belongs to a group. And they can be trained with a limited data set and offer spectacular results.
That’s All! I hope you like it.
Remember that the notebook is available on Kaggle.
How to create a Siamese Network to compare images
![]()
How To Create a Siamese Network With Keras to Compare Images was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI













![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


