
How Do Search Engines Work? Beginner’s Guide


Chapter 1
Mục Lục
Search engine basics
Before we get into the technical stuff, let’s first make sure we understand what search engines actually are, why they exist, and why any of this even matters.
What are search engines?
Search engines are tools that find and rank web content matching a user’s search query.
Each search engine consists of two main parts:
- Search index. A digital library of information about web pages.
- Search algorithm(s). Computer program(s) that rank matching results from the search index.
Examples of popular search engines include Google, Bing, and DuckDuckGo.
What is the aim of search engines?
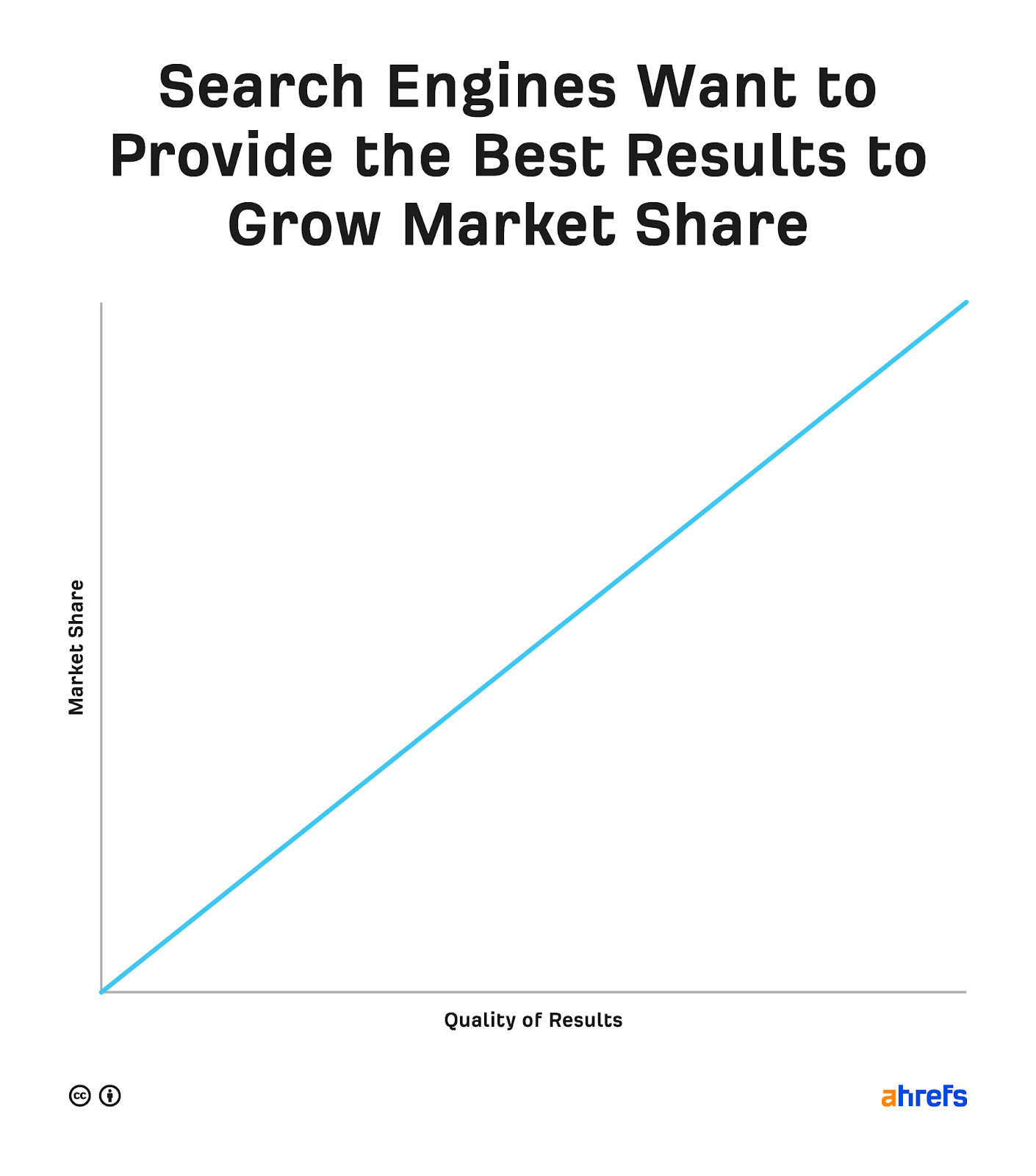
Every search engine aims to provide the best, most relevant results for users. That’s how they obtain or maintain market share—at least in theory.
How do search engines make money?
Search engines have two types of search results:
- Organic results from the search index. You can’t pay to be here.
- Paid results from advertisers. You can pay to be here.

Each time someone clicks on a paid search result, the advertiser pays the search engine. This is known as pay-per-click (PPC) advertising.
This is why market share matters. More users means more ad clicks and more revenue.
Why should you care how search engines work?
Understanding how search engines find, index and rank content will help you to rank your website in organic search results for relevant and popular keywords.
If you can rank high for these queries, you’ll get more clicks and organic traffic to your content.
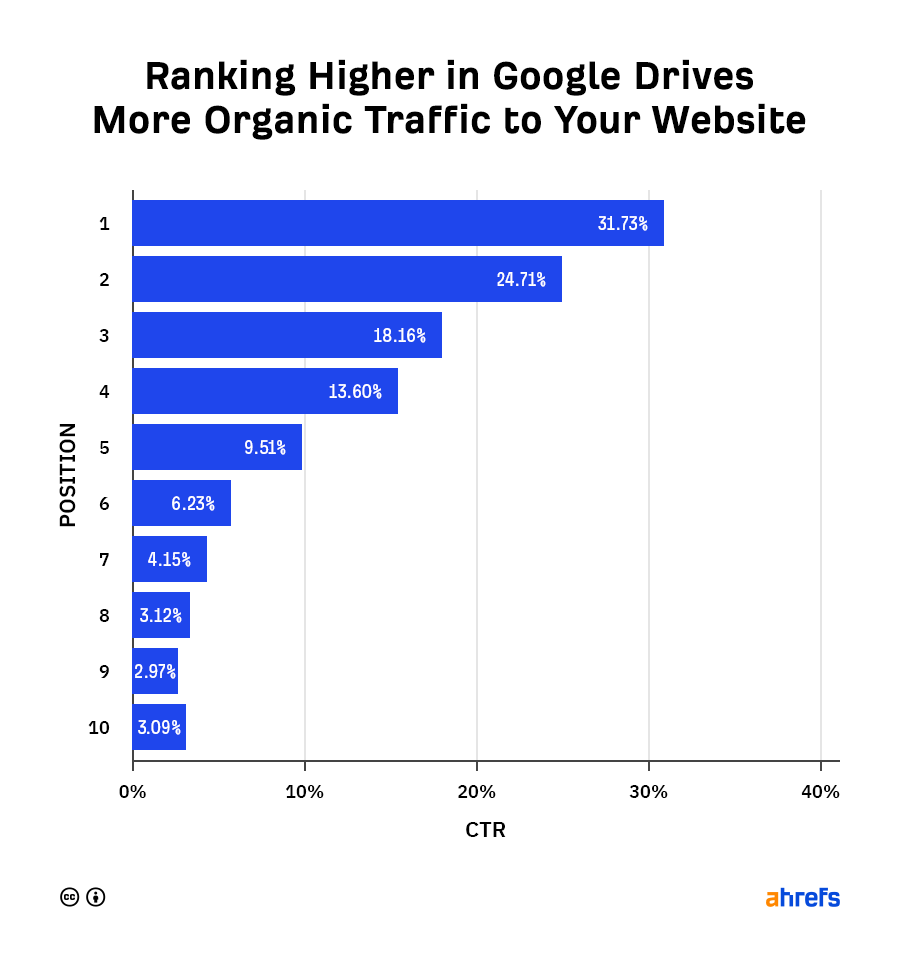
Which is the most popular search engine?
Google. It has a 92% market share.
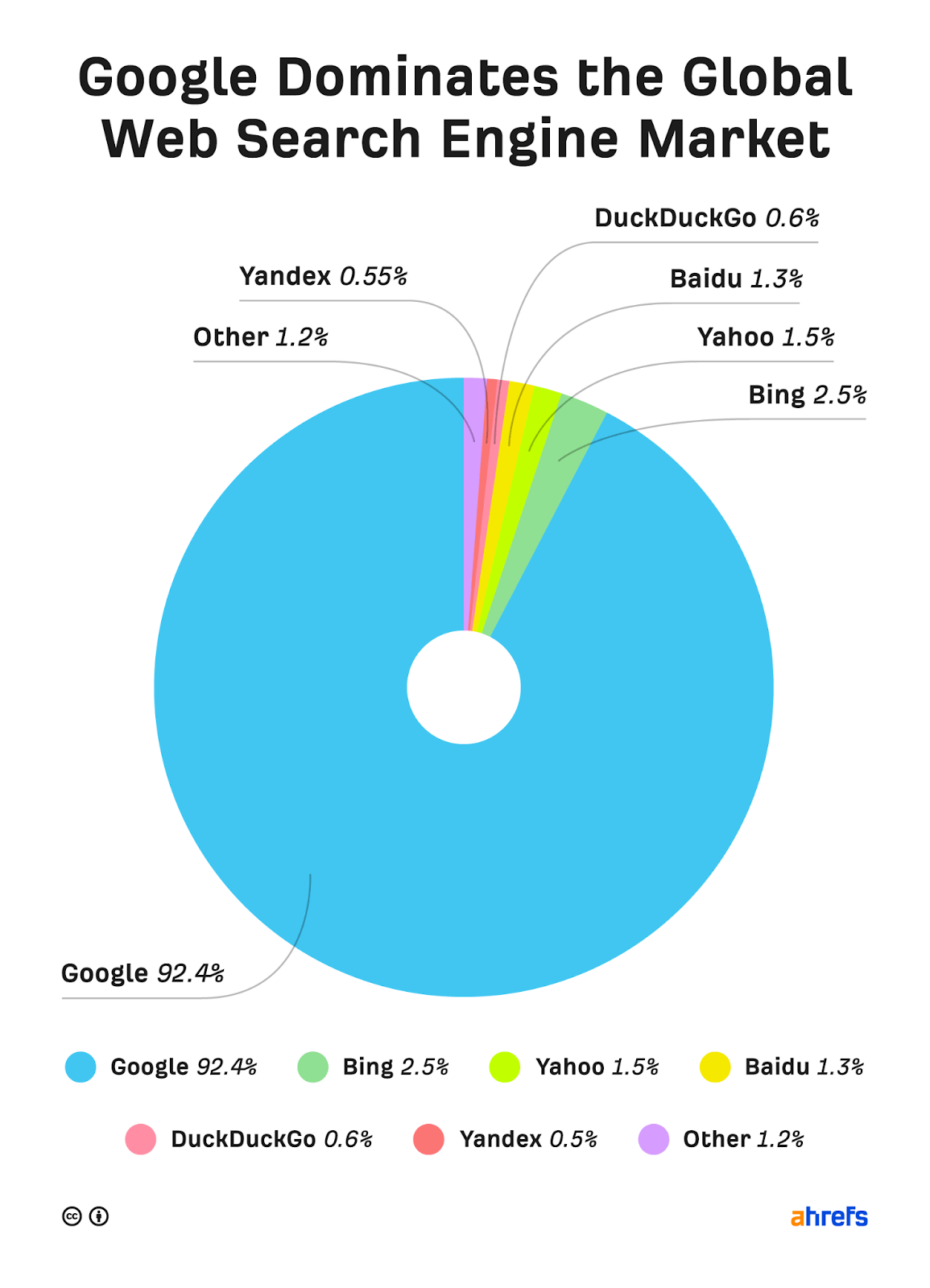
Google is the search engine that most SEO professionals and website owners care about because it has the potential to send more traffic their way than any other search engine.

Chapter 2
How search engines build their index
Most well-known search engines like Google and Bing have trillions of pages in their search indexes. So before we talk about ranking algorithms, let’s drill deeper into the mechanisms used to build and maintain a web index.
Here’s the basic process, courtesy of Google:

Let’s break this down, step by step:
- URLs
- Crawling
- Processing & rendering
- Indexing
Sidenote.
The process below applies specifically to Google, but it’s likely very similar for other web search engines like Bing. There are other types of search engines like Amazon, YouTube, and Wikipedia that only show results from their website.
The process below applies specifically to Google, but it’s likely very similar for other web search engines like Bing. There are other types of search engines like Amazon, YouTube, and Wikipedia that only show results from their website.
Step 1. URLs
Everything begins with a known list of URLs. Google discovers these through various processes, but the three most common ones are:
From backlinks
Google already has an index containing trillions of web pages. If someone adds a link to one of your pages from one of those web pages, they can find it from there.
You can see your website’s backlinks for free using Site Explorer with Ahrefs Webmaster Tools.
- Sign up for a free Ahrefs Webmaster Tools account
- Paste your domain into Site Explorer
- Go to the Backlinks report.
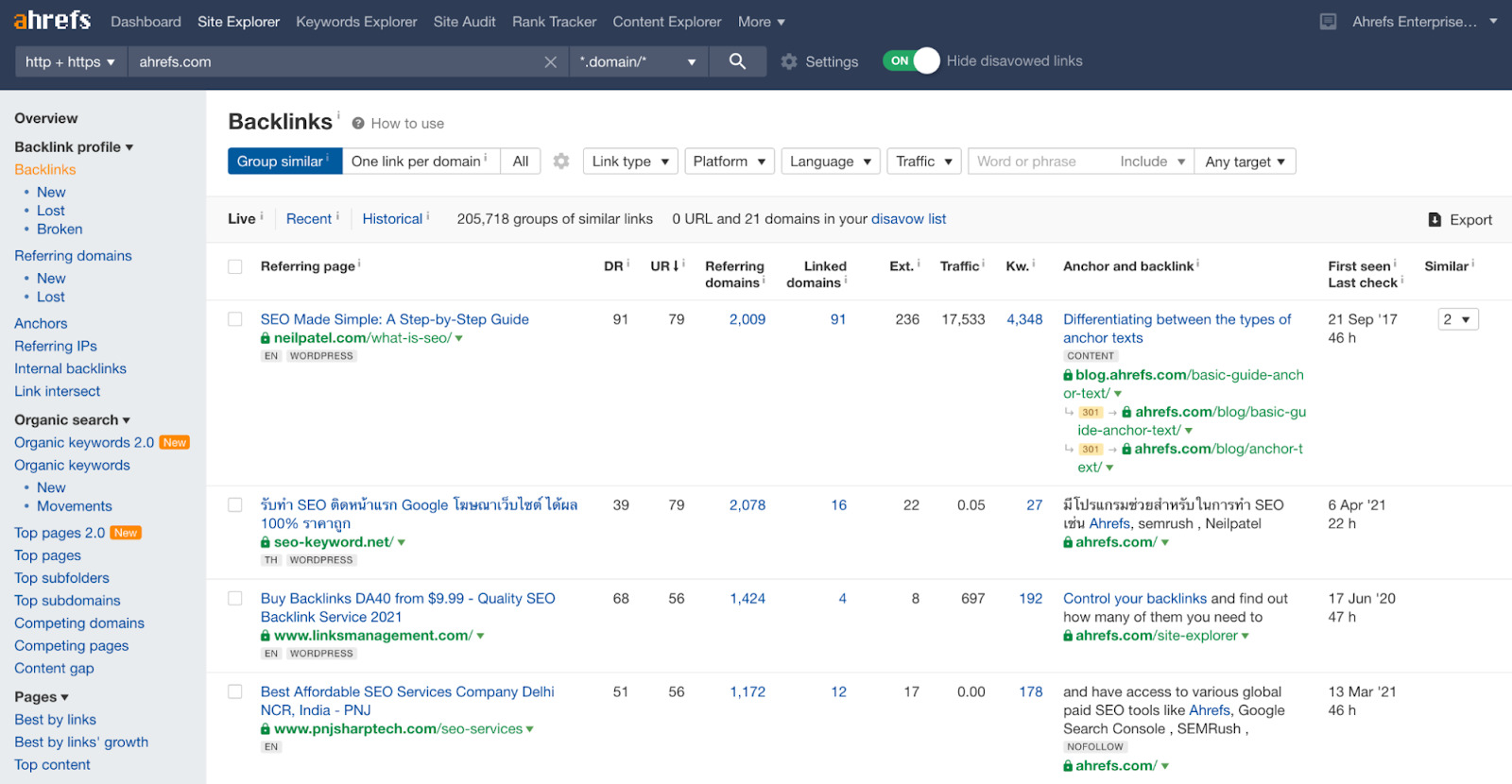
Our crawler is the second most active after Google,so you should see a reasonably complete view of your backlinks here.
From sitemaps
Sitemaps list all of the important pages on your website. If you submit your sitemap to Google, it may help them discover your website faster.
From URL submissions
Google also allows submissions of individual URLs via Google Search Console.
Step 2. Crawling
Crawling is where a computer bot called a spider (e.g., Googlebot) visits and downloads the discovered pages.
It’s important to note that Google doesn’t always crawl pages in the order they discover them.
Google queues URLs for crawling based on a few factors, including:
- the PageRank of the URL
- how often the URL changes
- whether or not it’s new
This is important because it means that search engines might crawl and index some of your pages before others. If you have a large website, it could take a while for search engines to fully crawl it.
Step 3. Processing
Processing is where Google works to understand and extract key information from crawled pages. Nobody outside of Google knows every detail about this process, but the important parts for our understanding are extracting links and storing content for indexing.
Google has to render pages to fully process them, which is where Google runs the page’s code to understand how it looks for users.
That said, some processing occurs before and after rendering—as you can see in the diagram.
Step 4. Indexing
Indexing is where processed information from crawled pages is added to a big database called the search index. This is essentially a digital library of trillions of webpages where Google’s search results come from.
That’s an important point. When you type a query into a search engine, you’re not directly searching the internet for matching results. You’re searching a search engine’s index of web pages. If a web page isn’t in the search index, search engine users won’t find it. That’s why getting your website indexed in major search engines like Google and Bing is so important.

Chapter 3
How search engines rank pages
Discovering, crawling, and indexing content is merely the first part of the puzzle. Search engines also need a way to rank matching results when a user performs a search. This is the job of search engine algorithms.
Each search engine has unique algorithms for ranking web pages. But as Google is by far the most widely used search engine (at least in the western world), that’s the one we’re going to focus on throughout the rest of this guide.
Google famously has 200+ ranking factors.
Nobody knows what all of these ranking factors are, but we do know about the key ones.
Let’s discuss a few of them.
- Backlinks
- Relevance
- Freshness
- Topical authority
- Page speed
- Mobile-friendliness
Backlinks
Backlinks are one of Google’s most important ranking factors.
Andrey Lipattsev, Search Quality Senior Strategist at Google, confirmed this during a live webinar in 2016. When asked about the two most important ranking factors, his response was simple: content and links.
Absolutely. I can tell you what they [the top two ranking factors] are. It is content. And it’s links pointing to your site.
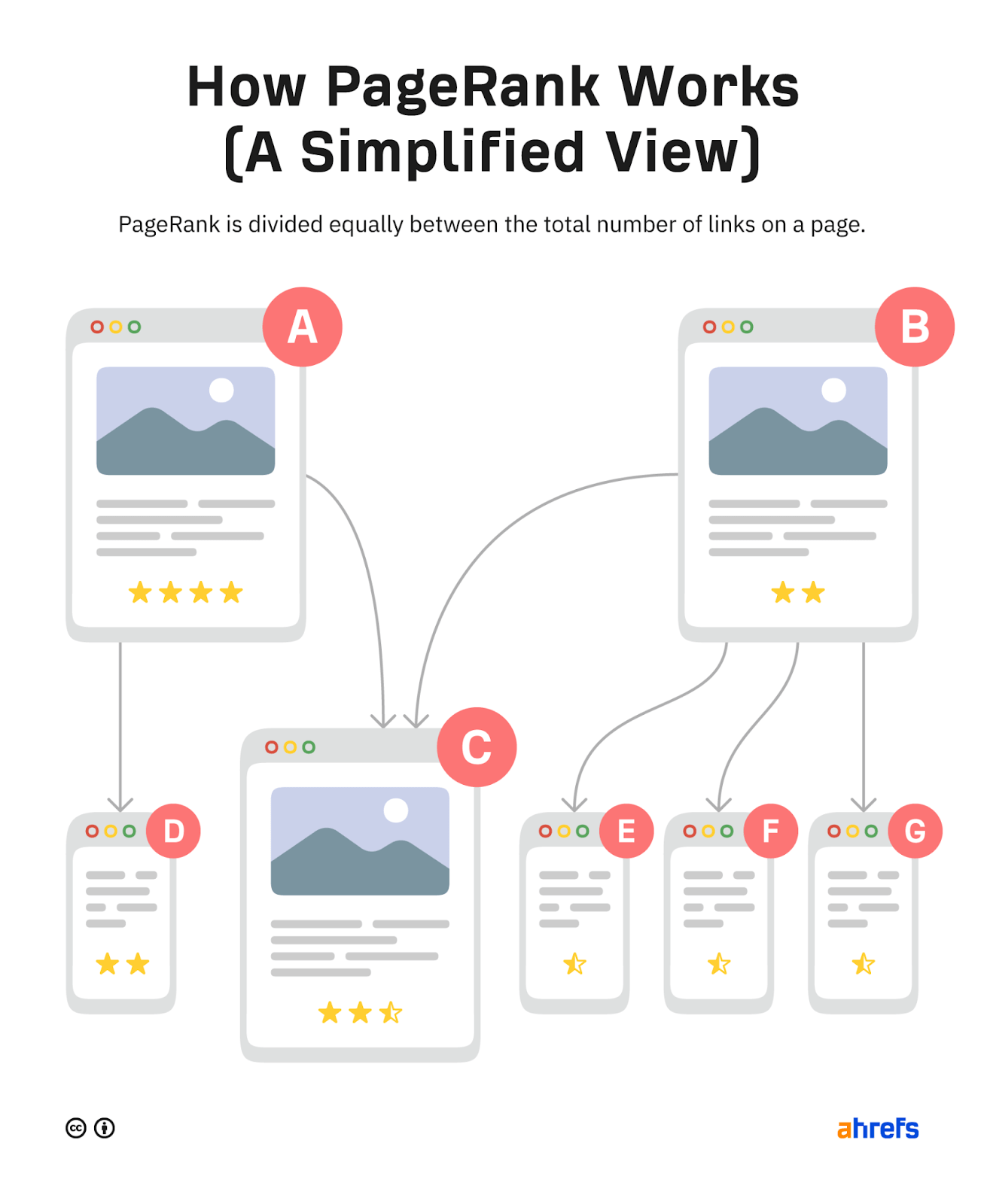
Links have been an important ranking factor in Google since 1997 when they introduced PageRank, a formula for judging the value of a web page based on the quantity and quality of backlinks pointing to it.
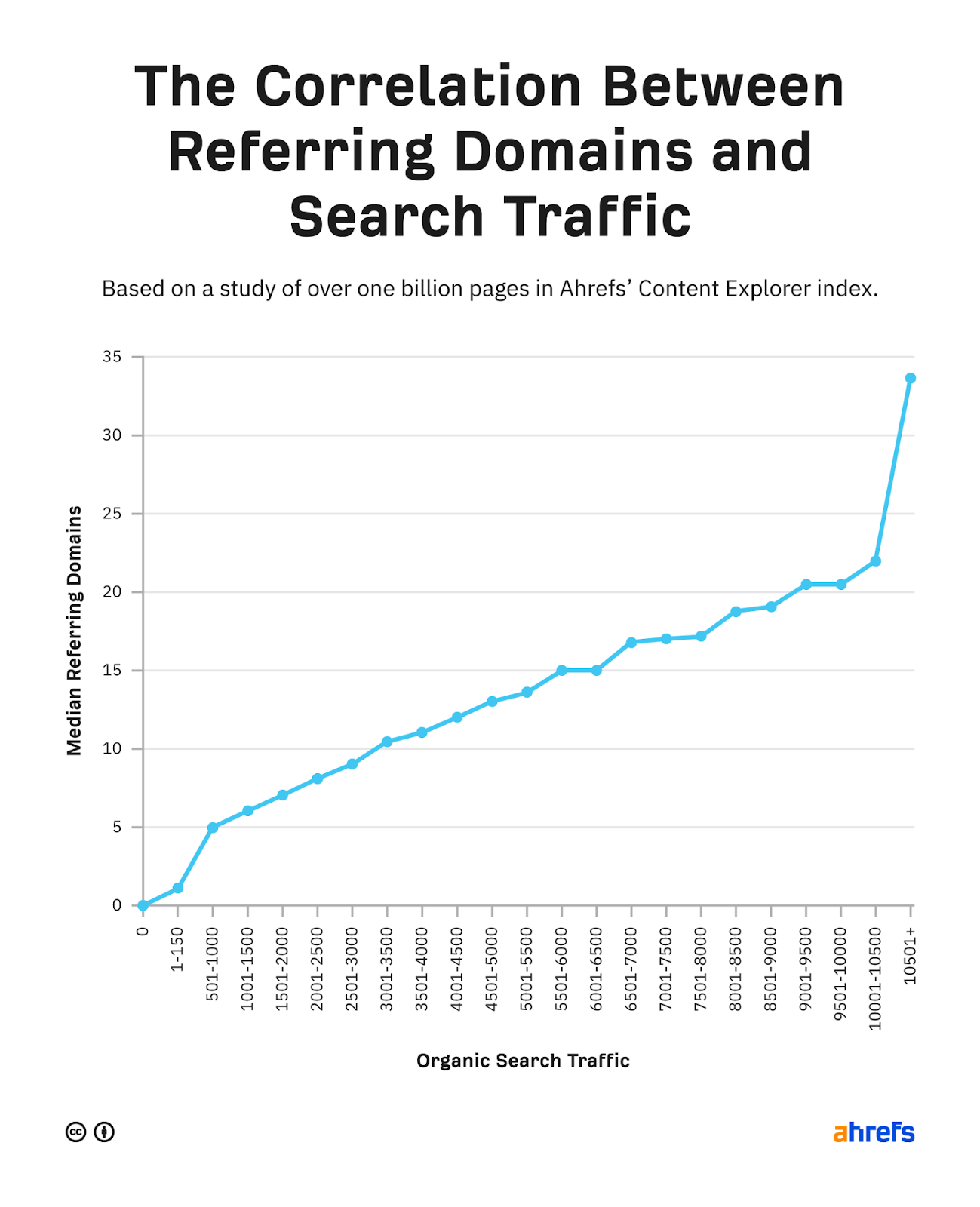
When we analyzed over one billion pages, we found a clear correlation between the number of websites linking to a page and the amount of organic traffic it gets from Google.
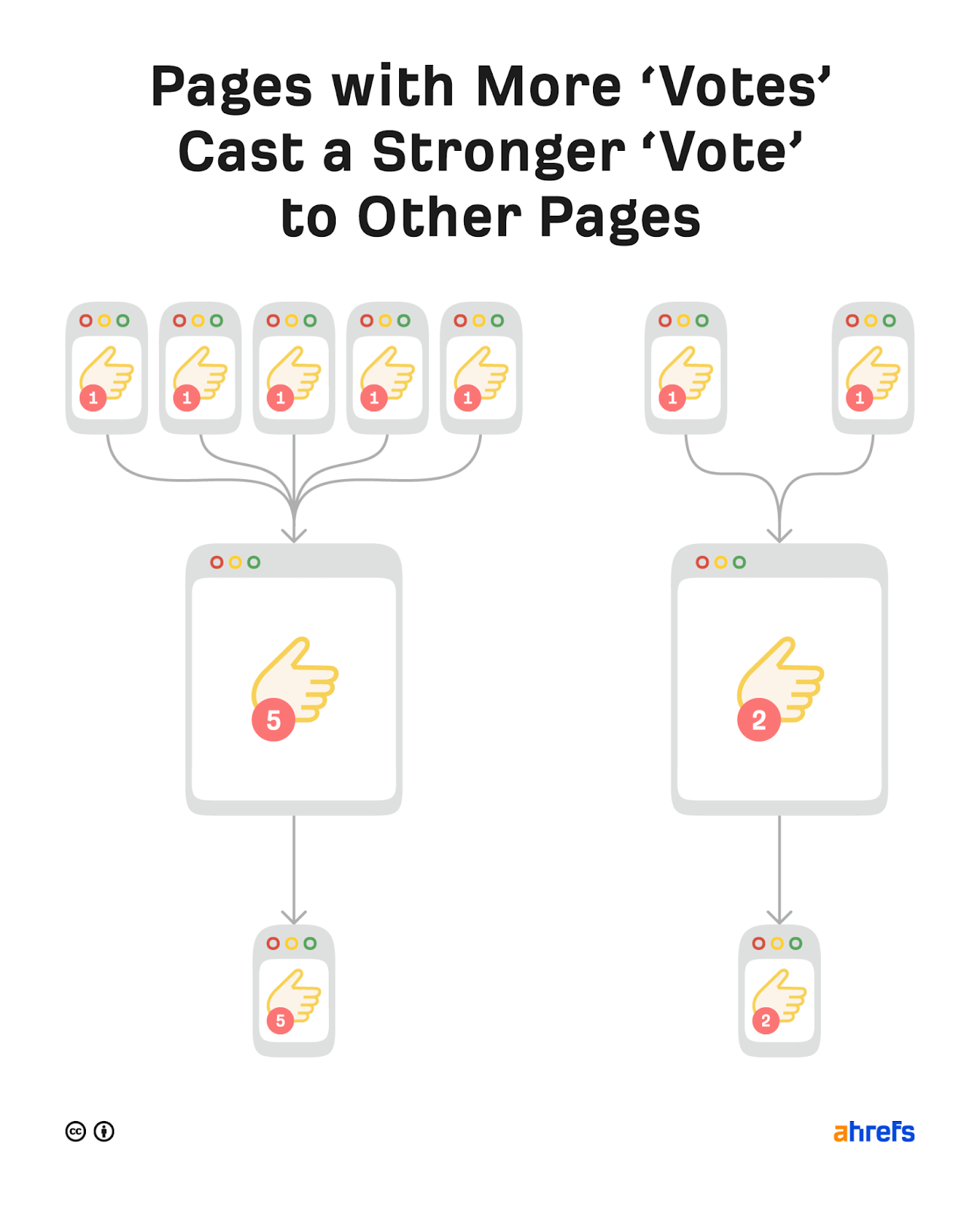
However it’s not all about quantity because not all backlinks are created equal. It’s perfectly possible for a page with a few high-quality backlinks to outrank a page with lots of lower-quality backlinks.
There are six key attributes of a good backlink.
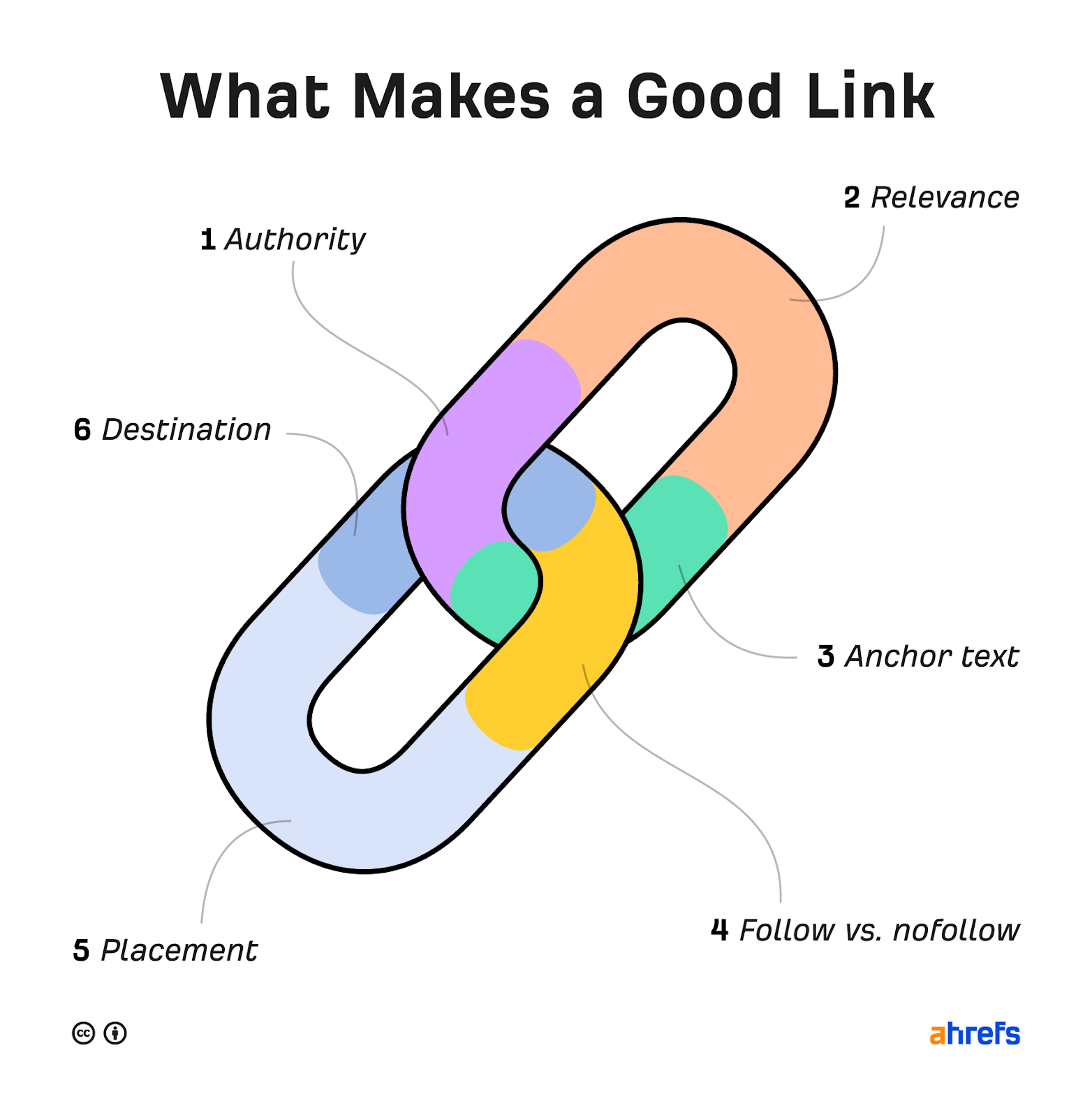
Let’s take a closer look at arguably the two most important ones: authority and relevance.
Link authority
Backlinks from authoritative pages and websites usually have the most impact on rankings.
How do you define authority? In the context of SEO, authoritative pages and websites are those that have many backlinks or “votes.”
In Ahrefs, we have two metrics for estimating the relative authority of websites and pages:
- Domain Rating (DR): The relative authority of a website on a scale from 0-100.
- URL Rating (UR): The relative authority of a page on a scale from 0-100.
You can check the authority of any website or web page in Ahrefs’ Site Explorer.
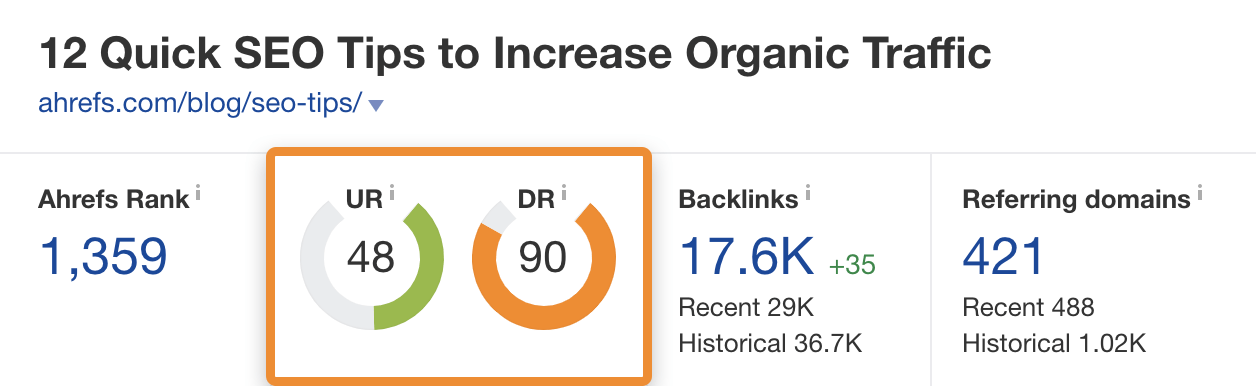
Link relevance
Links from relevant websites and web pages are usually the most valuable.
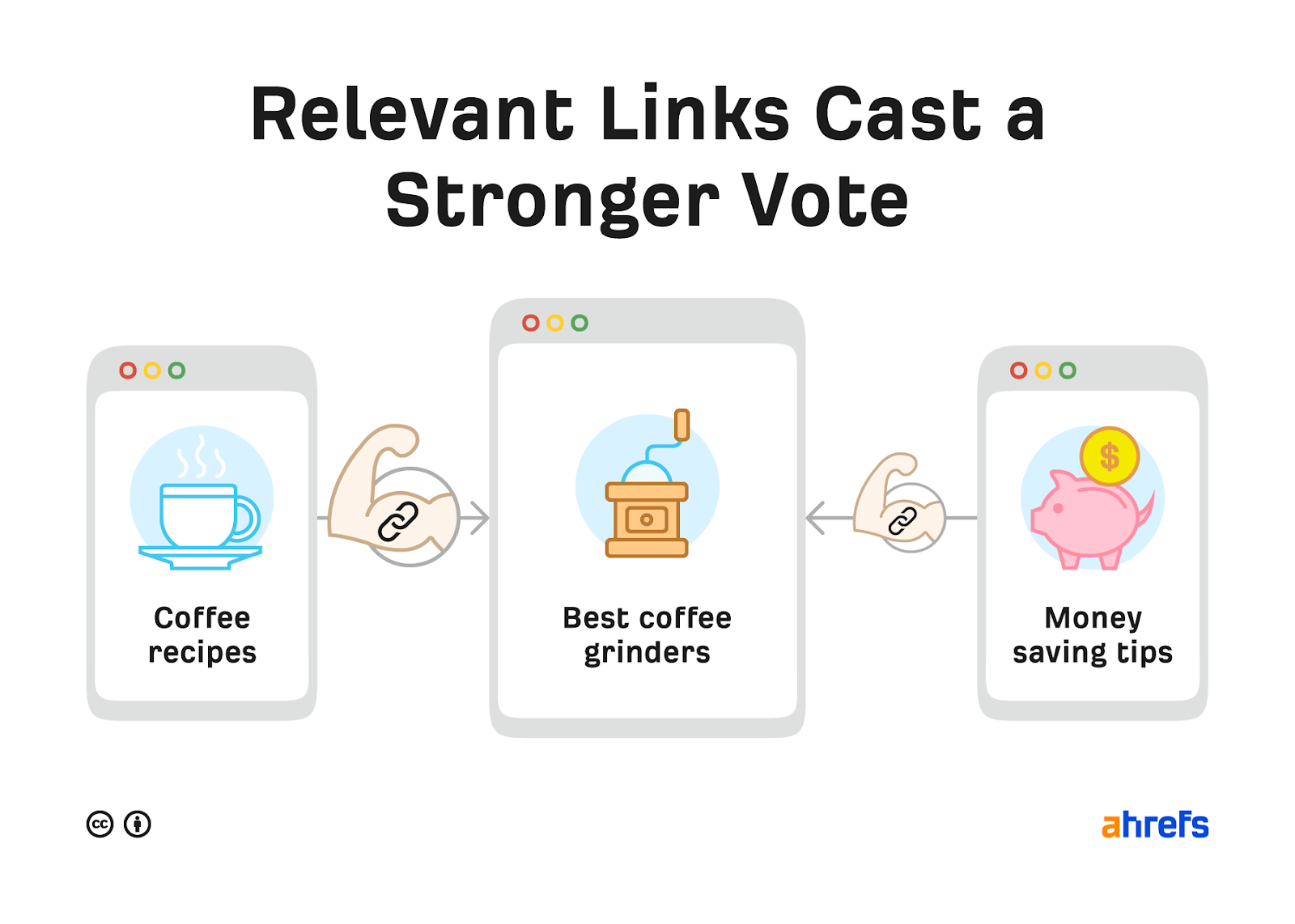
Google talks about relevance in the context of ranking useful pages on their page about how search works.
If other prominent websites on the subject link to the page, that’s a good sign that the information is of high quality.
If you’re wondering why relevance matters, think about how things work in the real world. You’d probably trust your chef friend’s advice when looking for the best italian restaurant over your vet friend’s advice. But if you were looking for cat food recommendations, it’d be the other way around.
Relevance
Google has many ways of determining page relevance.
At the most basic level, it looks for pages containing the same keywords as the search query.

But relevance goes way beyond keyword matching.
Google also uses interaction data to assess whether search results are relevant to queries. In other words, are searchers finding the page useful?

This is partly why all of the top results for “apple” are about the technology company, not the fruit. Google knows from interaction data that most searchers are looking for information about the former, not the latter.
Interaction data is far from the only way Google does this, though.
Google has invested in many technologies to help understand the relationships between entities like people, places, and things. The Knowledge Graph is one of these technologies, which is essentially a huge knowledgebase of entities and the relationships between them.
Both apple (fruit) and Apple (technology company) are entities in the Knowledge Graph.
Google uses the relationships between entities to better understand page relevance. A matching result for “apple” that talks about oranges and bananas is clearly about the fruit. But one that talks about iPhone, iPad, and iOS is clearly about the technology company.
It’s in part thanks to the Knowledge Graph that Google can go beyond keyword matching.
Sometimes you may even see search results that fail to mention seemingly important keywords from the query. For example, take the second result for “apple paper app,” which doesn’t mention the word “apple” anywhere on the page.
![]()
Google can tell it’s a relevant result partly because it mentions entities like iPhone and iPad that are undoubtedly closely related to Apple in the Knowledge Graph.
Sidenote.
Interaction data and the Knowledge Graph are not the only technologies Google uses to understand the relevance of a page to the search query. Much of the work is accomplished using technologies to understand the meaning and intent behind the query itself, such as BERT and RankBrain. Google even sometimes rewrites queries behind the scenes to deliver more relevant results.
Interaction data and the Knowledge Graph are not the only technologies Google uses to understand the relevance of a page to the search query. Much of the work is accomplished using technologies to understand the meaning and intent behind the query itself, such as BERT and RankBrain. Google even sometimes rewrites queries behind the scenes to deliver more relevant results.
Freshness
Freshness is a query-dependant ranking factor, meaning that it matters for some results more than others.
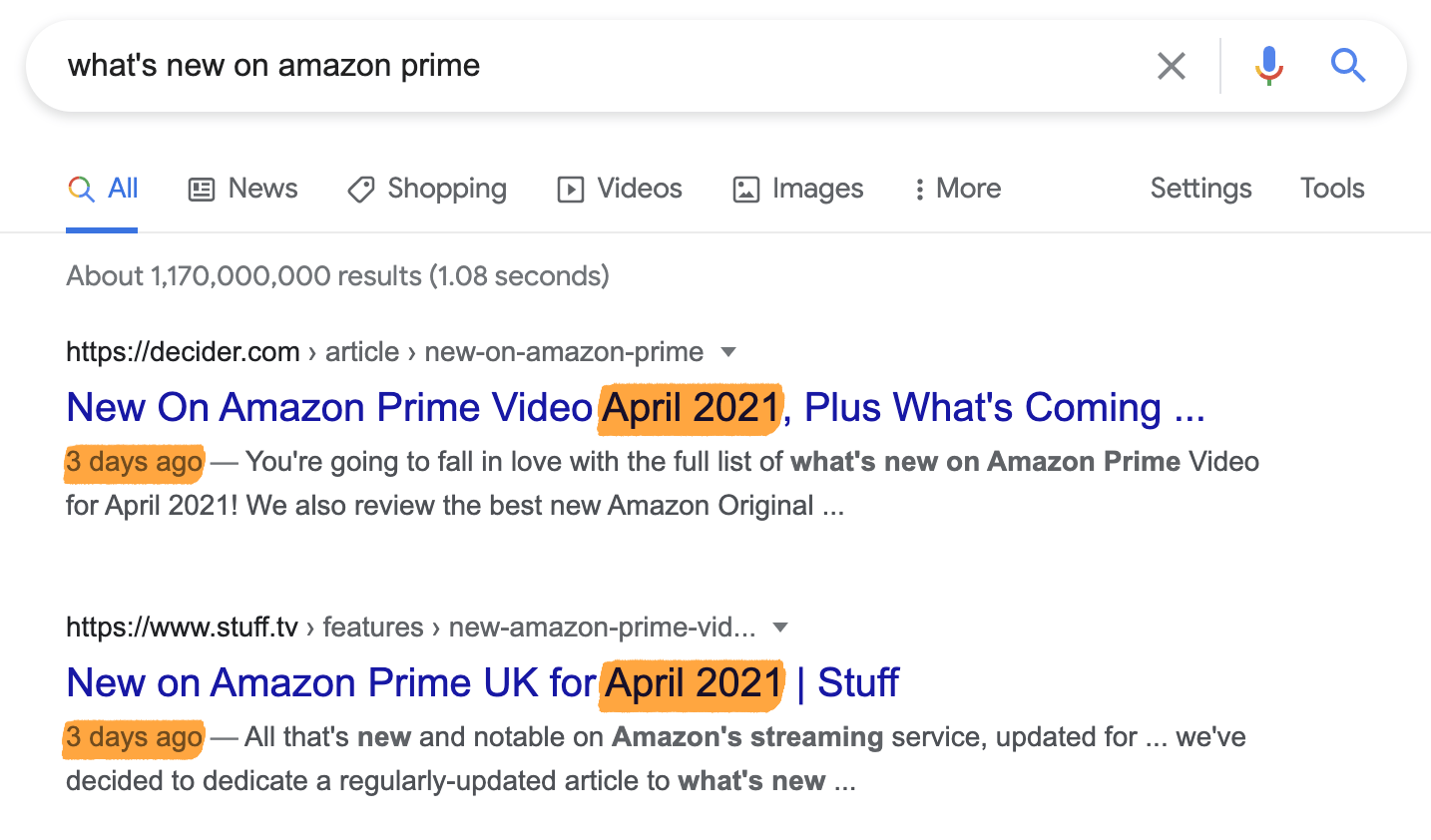
For a query like “what’s new on amazon prime,” freshness is important because searchers want to know about recently-added movies and TV shows. That’s likely why Google ranks newly-published or updated search results higher.
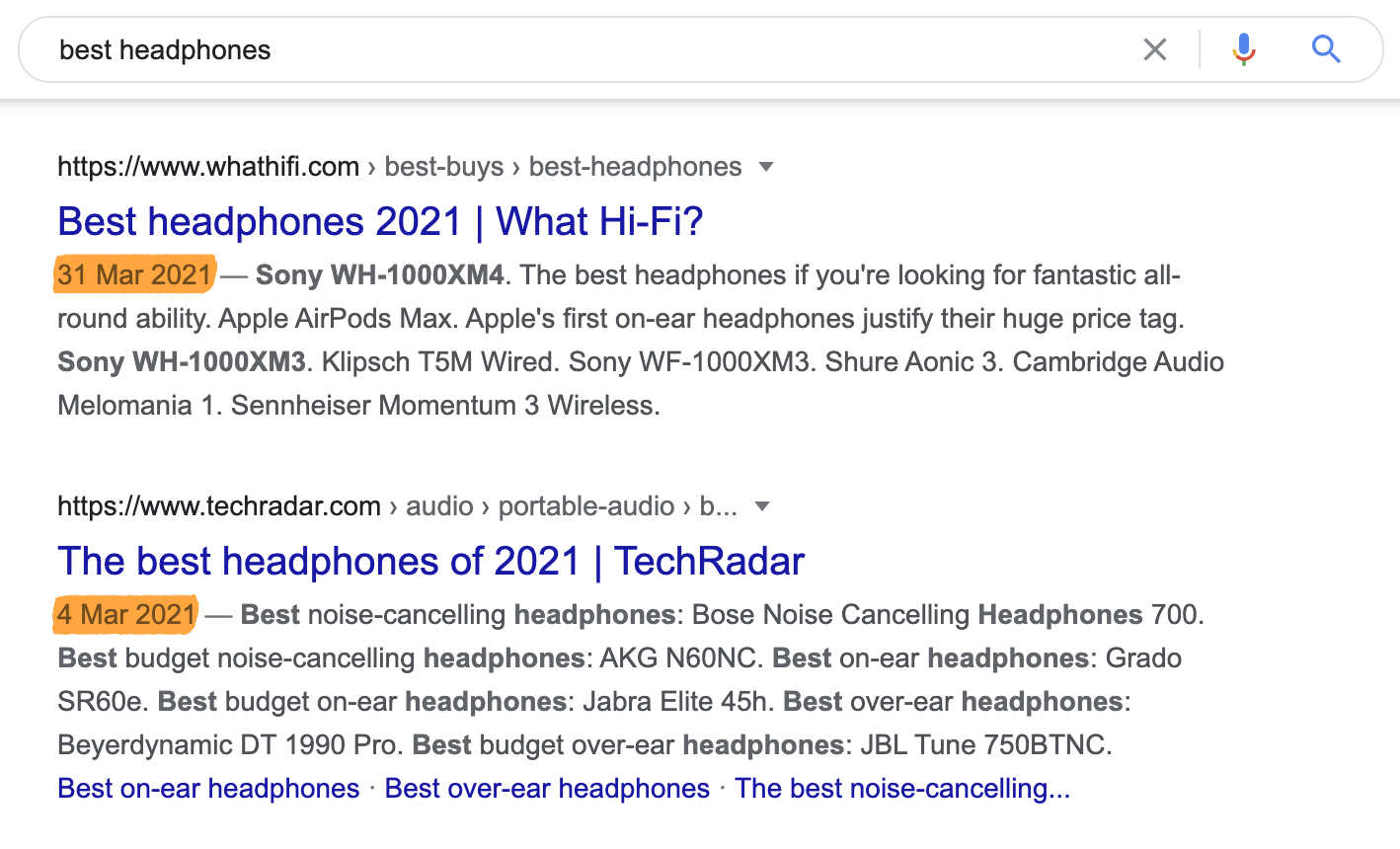
For queries like “best headphones,” freshness matters but not quite as much. Headphone technology moves fast so a result from 2015 won’t be much use, but a post published 2-3 months ago will still be useful.
Google knows this and shows results that were updated or published in the past few months.
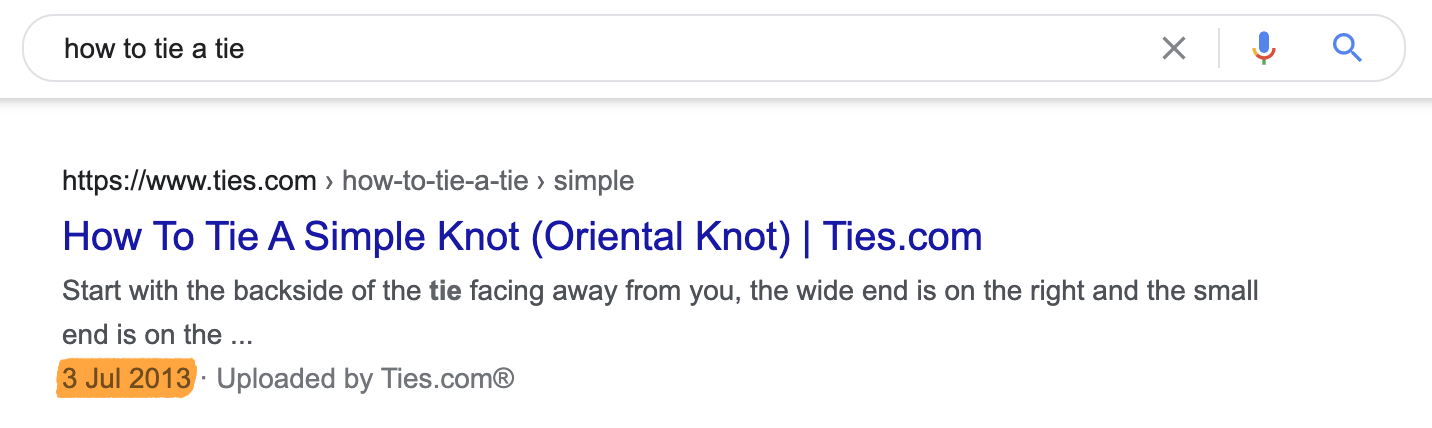
There are also queries where the freshness of results is mostly irrelevant, such as “how to tie a tie.” Nothing has changed about this process in decades so it doesn’t matter if the search results are from yesterday or 1998. Google knows this and has no qualms about ranking posts published years ago.
Topical authority
Google wants to rank content from websites with authority on the topic. This means that Google might view a website as a good source of results for queries about one topic but not another.
Google talks about this in one of their patents:
Whether the search system considers a site to be authoritative will typically be query-dependent. […] the search system can consider the site for the Centers for Disease Control, “cdc.gov,” to be an authoritative site for the query “CDC mosquito stop bites,” but may not consider the same site to be authoritative for the query “restaurant recommendations”.
Although this is just one of many patents filed by Google, we see evidence that “topical authority” matters in the search results for many queries.
Just look at the results for “sous vide vacuum sealer.”
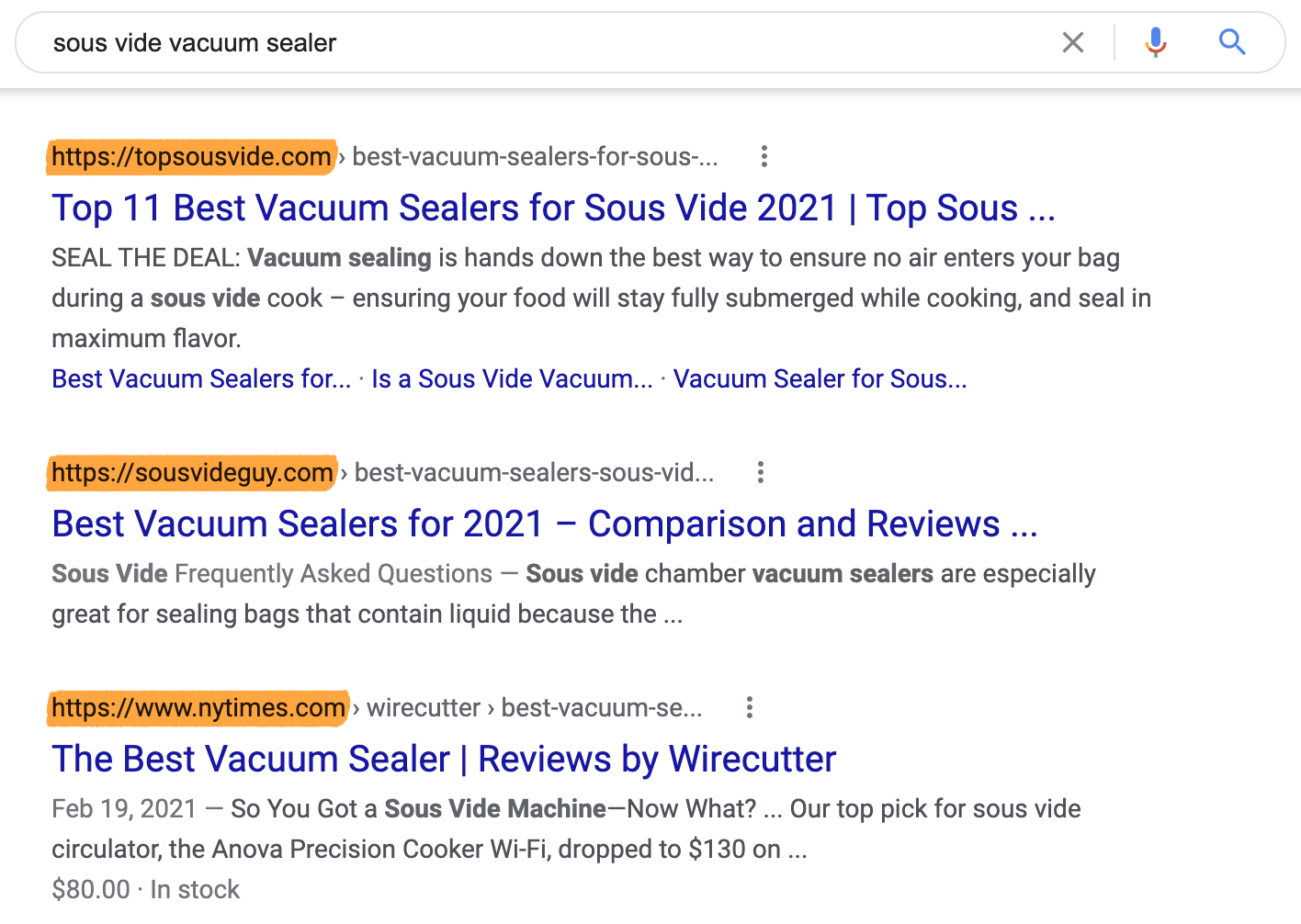
Here, we see two small niche sites about sous vide cooking outranking The New York Times.
Although there are undoubtedly other factors at play here, it seems likely that ‘topical authority’ is one of the reasons these sites rank where they do.
This is probably why Google’s SEO starter guide tells website owners to:
Cultivate a reputation for expertise and trustworthiness in a specific area.
Page speed
Nobody likes waiting for pages to load, and Google knows it. That’s why they made page speed a ranking factor for desktop searches in 2010, and for mobile searches in 2018.
Many people get hung up about page speed, so it’s worth noting that your pages don’t need to be lightning-fast to rank. Google says that page speed is only a problem for pages that “deliver the slowest experience to users.”
In other words, shaving a few milliseconds off a site that’s already fast is unlikely to boost rankings. It just needs to be fast enough not to negatively impact users.
You can check the speed of any web page in PageSpeed Insights, which also generates suggestions to make the page faster.

PageSpeed Insights also shows how your page fares when it comes to Core Web Vitals.
Core Web Vitals are made up of three metrics that assess the loading performance, interactivity and visual stability of your web pages. Google has confirmed that Core Web Vitals will be a ranking signal as of June 2021.
You can see the performance of all pages on your website using the Core Web Vitals report in Google Search Console.
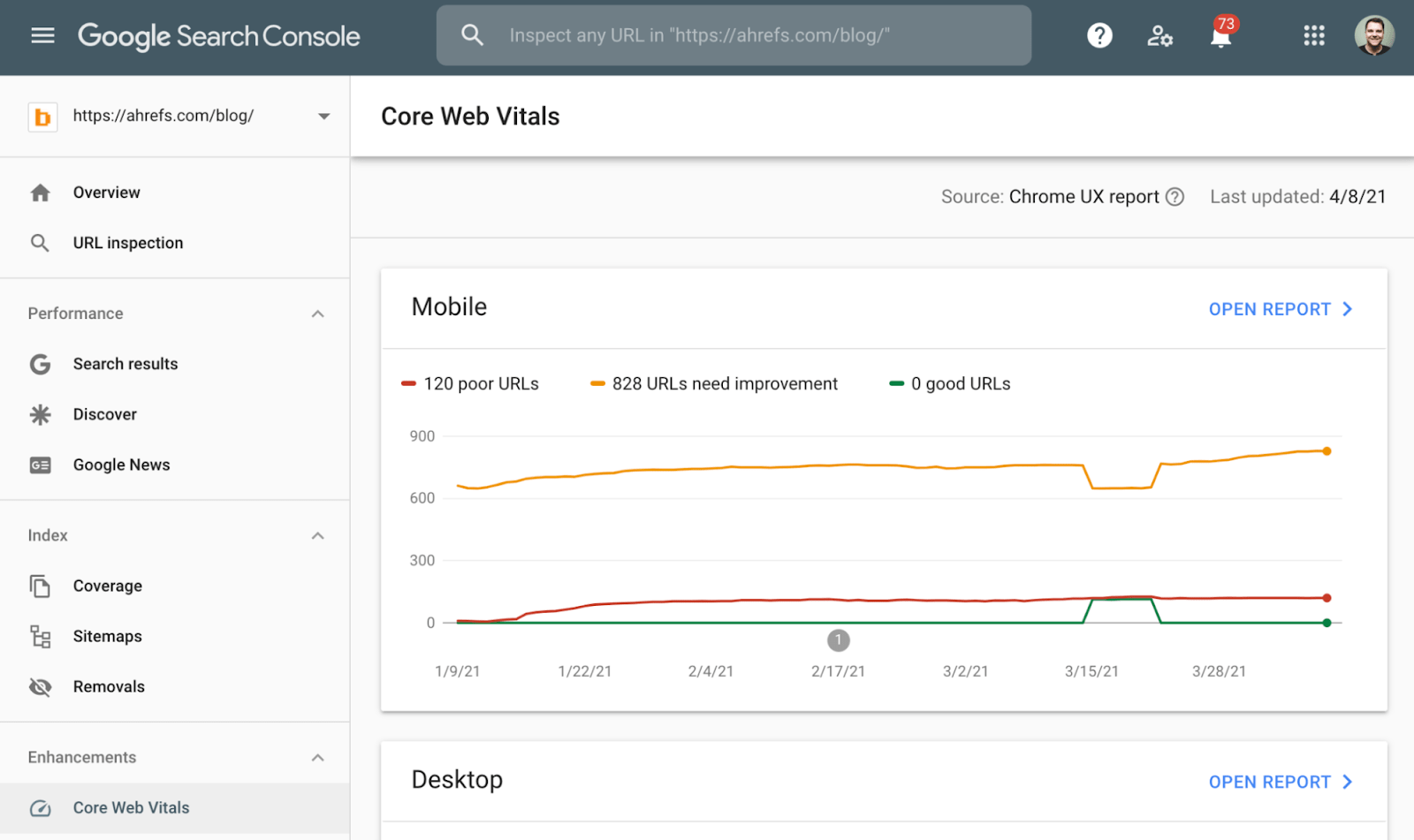
If many URLs are performing poorly or need improvement, talk to a developer.
Mobile-friendliness
65% of Google searches happen on mobile devices. That’s why mobile-friendliness has been a factor on mobile since 2015.
Since 2019, mobile-friendliness is also a ranking factor for desktop searches thanks to Google’s switch to mobile-first indexing. This means that Google “predominantly uses the mobile version of the content for indexing and ranking” across all devices.
In other words, a lack of mobile-friendliness can affect rankings—everywhere.
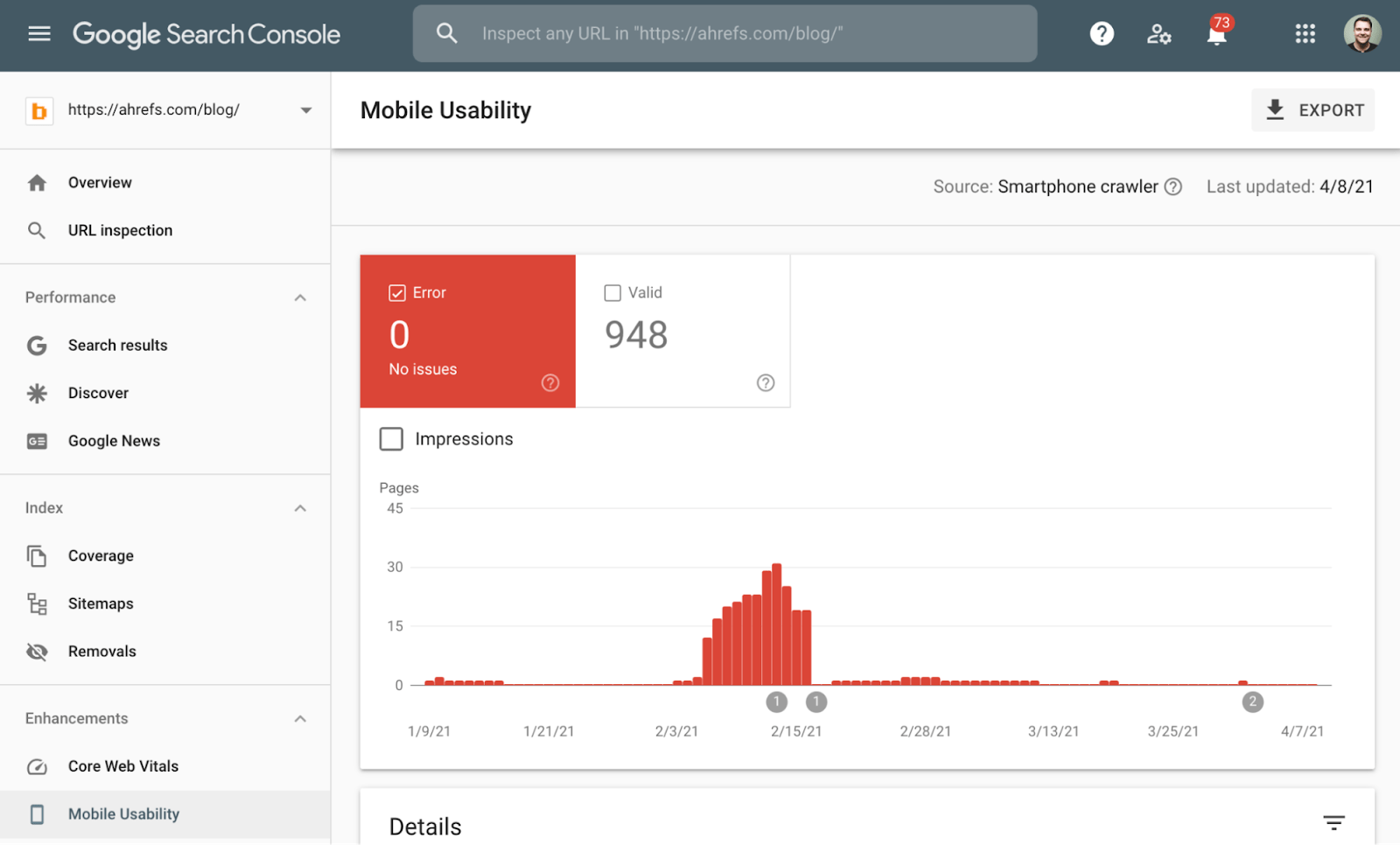
You can check the mobile-friendliness of any web page using Google’s Mobile-Friendly Test tool, or in the Mobile Usability report in Google Search Console.

Chapter 4
How search engines personalize search results
Search engines understand that different results appeal to different people. That’s why they tailor their results for each user.
If you’ve ever searched for the same thing on multiple devices or browsers, you’ve probably seen the effects of this personalization. Results often show up in different positions depending on various factors.
It’s because of this personalization that if you’re doing SEO, you’re better off using a dedicated tool like Ahrefs’ Rank Tracker to track ranking positions. The reported positions in these tools are likely to be closer to the truth because they browse the web in a way that doesn’t give search engines much useful information for personalization.
How do search engines personalize results?
Google states that “information such as your location, past search history and search settings all help [us] to tailor your results to what is most useful and relevant for you in that moment.”
Let’s take a closer look at these three things.
1. Location
If you search for something like “italian restaurant,” all the results in the map pack are local restaurants.
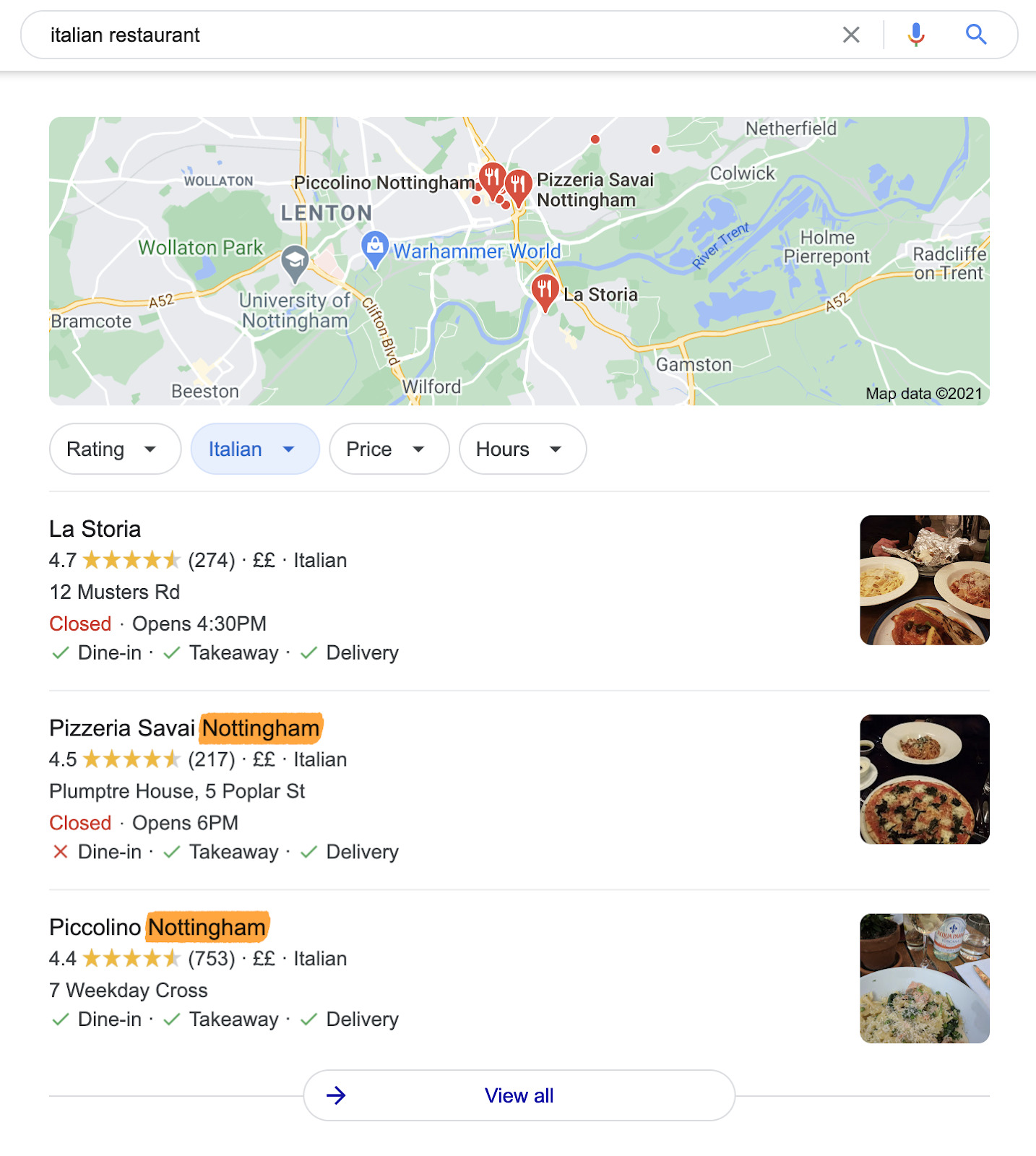
Google does this because you’re unlikely to fly halfway around the world for lunch.
But Google also uses your location to personalize search results outside of the map pack. If we scroll down on our search for “italian restaurant,” even the results from TripAdvisor are personalized, and we see that many of the top-ranking results are websites from local restaurants.
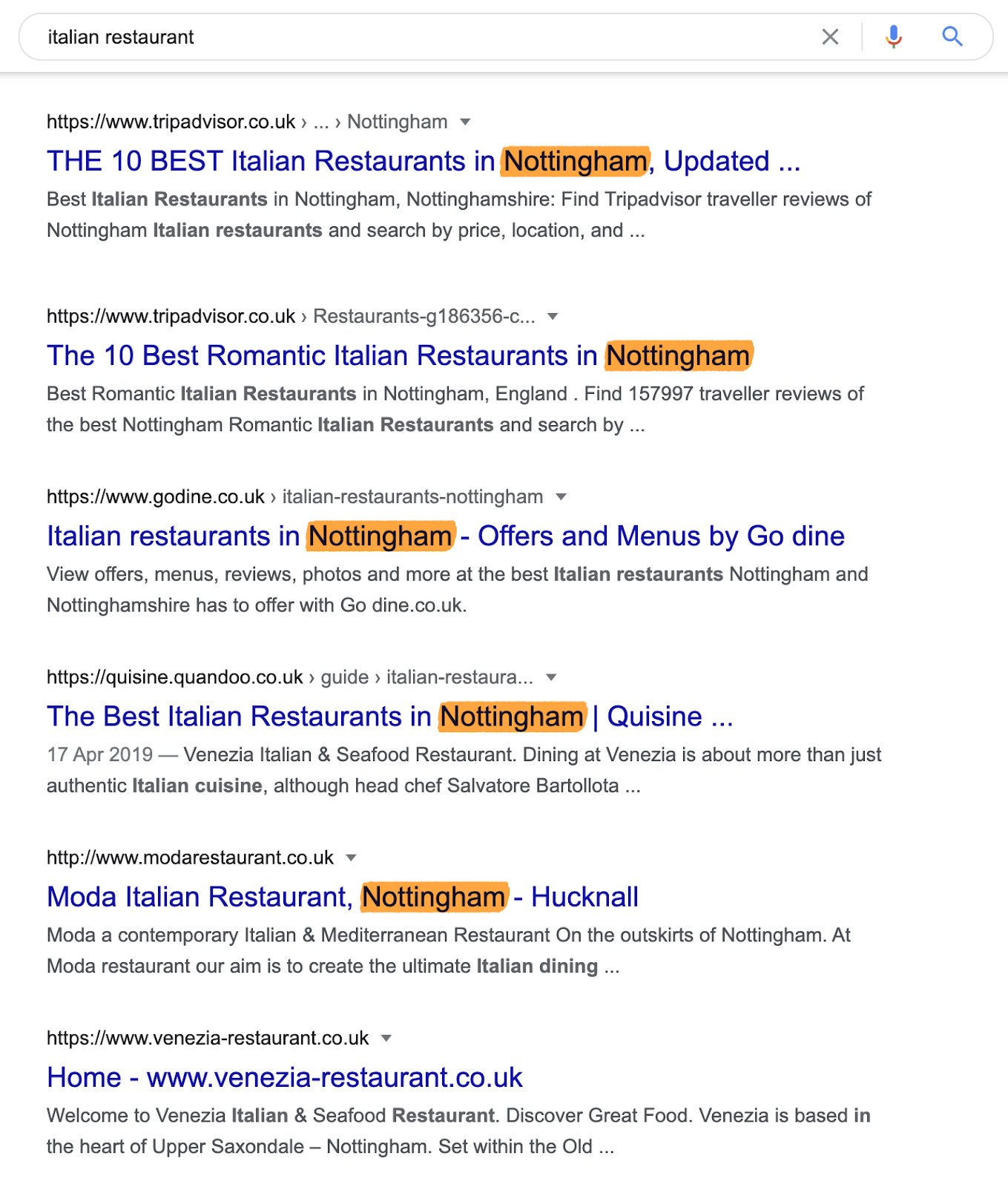
It’s a similar story for a query like “buy a house.” Google returns pages with local listings instead of national ones because you probably don’t want to relocate to a different country.
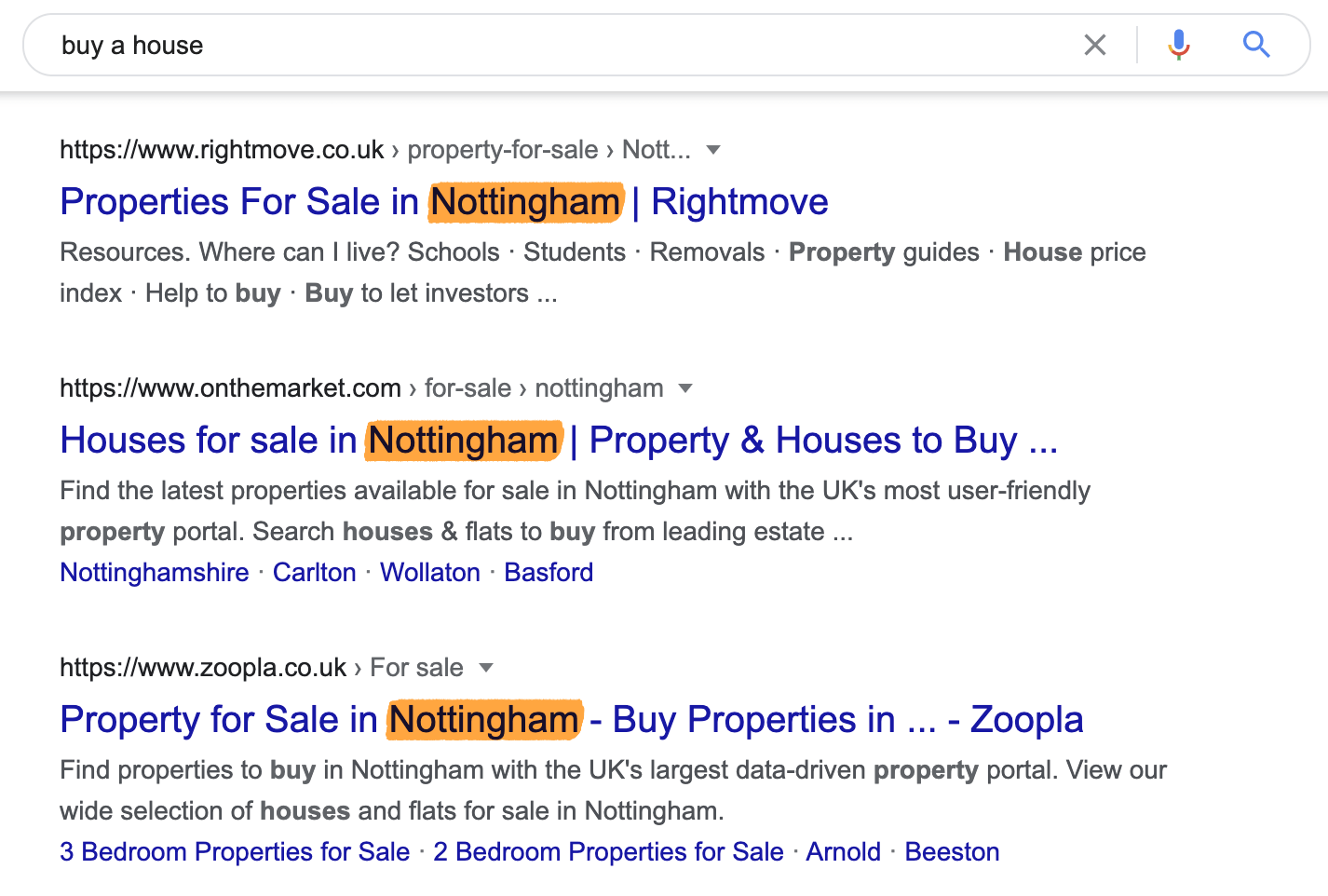
Your location impacts results for local queries so dramatically that there’s virtually no overlap when searching for the same thing from two different locations.
2. Language
Google knows that there’s no point showing English results to Spanish users. That’s why Google ranks the English version of our YouTube SEO tutorial for English searches and the Spanish version for Spanish searches.
However, Google is somewhat reliant on website owners to do this. If you have pages in multiple languages, Google might not realize that’s the case unless you tell them.
You can do this with an HTML attribute called hreflang.
Hreflang is a bit complicated and far beyond the scope of this guide, but basically it’s a small piece of code indicating the relationship between multiple versions of the same page in different languages.
3. Search history
Perhaps the most obvious example of Google using search history to personalize results is when it ‘ranks’ a previously clicked result higher next time you run the same search.
It doesn’t always happen, but it seems to be quite common—especially if you click or visit the page multiple times in a short period.
Let’s wrap this up
Understanding how search engines work is the first step towards ranking higher in Google and getting more traffic. If search engines can’t find, crawl and index your pages, you’re dead in the water before you even start.
If you want to know how to do that, and how to start optimizing your website for SEO, read our guide to SEO basics.
Got questions? Let me know in the comments or on Twitter.














![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


