
Generative Adversarial Network (GAN) – GeeksforGeeks
A Generative Adversarial Network (GAN) is a deep learning architecture that consists of two neural networks competing against each other in a zero-sum game framework. The goal of GANs is to generate new, synthetic data that resembles some known data distribution.
Mục Lục
1.Components:
- Generator network: creates synthetic data
- Discriminator network: evaluates the synthetic data and tries to determine if it’s real or fake
2.Training:
- The generator network produces synthetic data and the discriminator network evaluates it.
- The generator is trained to fool the discriminator and the discriminator is trained to correctly identify real and fake data.
- This process continues until the generator produces data that is indistinguishable from real data.
3.Applications:
- Image synthesis
- Text-to-Image synthesis
- Image-to-Image translation
- Anomaly detection
- Data augmentation
4.Limitations:
- Training can be unstable and prone to mode collapse, where the generator produces limited variations of synthetic data.
- GANs can be difficult to train and require a lot of computational resources.
- GANs can generate unrealistic or irrelevant synthetic data if the generator and discriminator are not properly trained.
Generative Adversarial Networks (GANs) are a powerful class of neural networks that are used for unsupervised learning. It was developed and introduced by Ian J. Goodfellow in 2014. GANs are basically made up of a system of two competing neural network models which compete with each other and are able to analyze, capture and copy the variations within a dataset. Why were GANs developed in the first place? It has been noticed most of the mainstream neural nets can be easily fooled into misclassifying things by adding only a small amount of noise into the original data. Surprisingly, the model after adding noise has higher confidence in the wrong prediction than when it predicted correctly. The reason for such adversary is that most machine learning models learn from a limited amount of data, which is a huge drawback, as it is prone to overfitting. Also, the mapping between the input and the output is almost linear. Although, it may seem that the boundaries of separation between the various classes are linear, but in reality, they are composed of linearities and even a small change in a point in the feature space might lead to misclassification of data. How does GANs work? Generative Adversarial Networks (GANs) can be broken down into three parts:
- Generative: To learn a generative model, which describes how data is generated in terms of a probabilistic model.
- Adversarial: The training of a model is done in an adversarial setting.
- Networks: Use deep neural networks as the artificial intelligence (AI) algorithms for training purpose.
In GANs, there is a generator and a discriminator. The Generator generates fake samples of data(be it an image, audio, etc.) and tries to fool the Discriminator. The Discriminator, on the other hand, tries to distinguish between the real and fake samples. The Generator and the Discriminator are both Neural Networks and they both run in competition with each other in the training phase. The steps are repeated several times and in this, the Generator and Discriminator get better and better in their respective jobs after each repetition. The working can be visualized by the diagram given below: 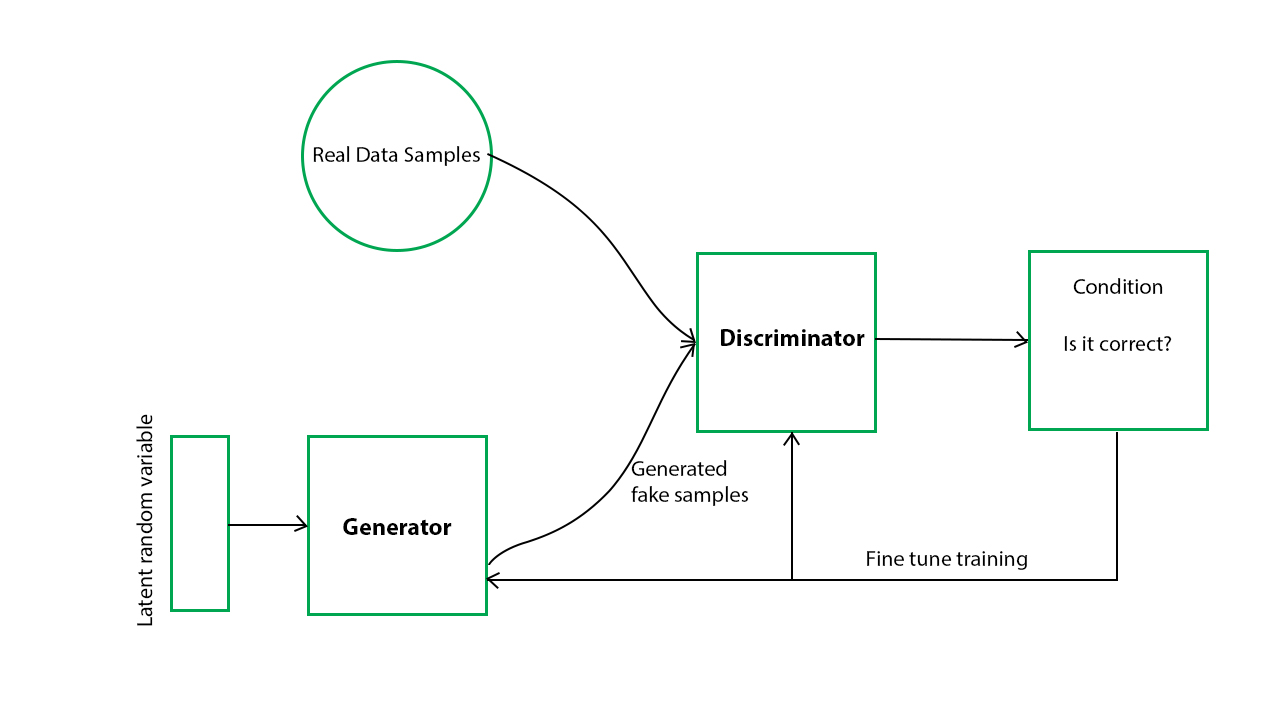 Here, the generative model captures the distribution of data and is trained in such a manner that it tries to maximize the probability of the Discriminator in making a mistake. The Discriminator, on the other hand, is based on a model that estimates the probability that the sample that it got is received from the training data and not from the Generator. The GANs are formulated as a minimax game, where the Discriminator is trying to minimize its reward V(D, G) and the Generator is trying to minimize the Discriminator’s reward or in other words, maximize its loss. It can be mathematically described by the formula below:
Here, the generative model captures the distribution of data and is trained in such a manner that it tries to maximize the probability of the Discriminator in making a mistake. The Discriminator, on the other hand, is based on a model that estimates the probability that the sample that it got is received from the training data and not from the Generator. The GANs are formulated as a minimax game, where the Discriminator is trying to minimize its reward V(D, G) and the Generator is trying to minimize the Discriminator’s reward or in other words, maximize its loss. It can be mathematically described by the formula below: 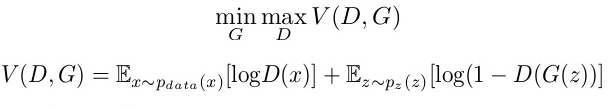 where, G = Generator D = Discriminator Pdata(x) = distribution of real data P(z) = distribution of generator x = sample from Pdata(x) z = sample from P(z) D(x) = Discriminator network G(z) = Generator network So, basically, training a GAN has two parts:
where, G = Generator D = Discriminator Pdata(x) = distribution of real data P(z) = distribution of generator x = sample from Pdata(x) z = sample from P(z) D(x) = Discriminator network G(z) = Generator network So, basically, training a GAN has two parts:
- Part 1: The Discriminator is trained while the Generator is idle. In this phase, the network is only forward propagated and no back-propagation is done. The Discriminator is trained on real data for n epochs, and see if it can correctly predict them as real. Also, in this phase, the Discriminator is also trained on the fake generated data from the Generator and see if it can correctly predict them as fake.
- Part 2: The Generator is trained while the Discriminator is idle. After the Discriminator is trained by the generated fake data of the Generator, we can get its predictions and use the results for training the Generator and get better from the previous state to try and fool the Discriminator.
- Vanilla GAN: This is the simplest type GAN. Here, the Generator and the Discriminator are simple multi-layer perceptrons. In vanilla GAN, the algorithm is really simple, it tries to optimize the mathematical equation using stochastic gradient descent.
- Conditional GAN (CGAN): CGAN can be described as a deep learning method in which some conditional parameters are put into place. In CGAN, an additional parameter ‘y’ is added to the Generator for generating the corresponding data. Labels are also put into the input to the Discriminator in order for the Discriminator to help distinguish the real data from the fake generated data.
- Deep Convolutional GAN (DCGAN): DCGAN is one of the most popular also the most successful implementation of GAN. It is composed of ConvNets in place of multi-layer perceptrons. The ConvNets are implemented without max pooling, which is in fact replaced by convolutional stride. Also, the layers are not fully connected.
- Laplacian Pyramid GAN (LAPGAN): The Laplacian pyramid is a linear invertible image representation consisting of a set of band-pass images, spaced an octave apart, plus a low-frequency residual. This approach uses multiple numbers of Generator and Discriminator networks and different levels of the Laplacian Pyramid. This approach is mainly used because it produces very high-quality images. The image is down-sampled at first at each layer of the pyramid and then it is again up-scaled at each layer in a backward pass where the image acquires some noise from the Conditional GAN at these layers until it reaches its original size.
- Super Resolution GAN (SRGAN): SRGAN as the name suggests is a way of designing a GAN in which a deep neural network is used along with an adversarial network in order to produce higher resolution images. This type of GAN is particularly useful in optimally up-scaling native low-resolution images to enhance its details minimizing errors while doing so.
Advantages of Generative Adversarial Networks (GANs):
- Synthetic data generation: GANs can generate new, synthetic data that resembles some known data distribution, which can be useful for data augmentation, anomaly detection, or creative applications.
- High-quality results: GANs can produce high-quality, photorealistic results in image synthesis, video synthesis, music synthesis, and other tasks.
- Unsupervised learning: GANs can be trained without labeled data, making them suitable for unsupervised learning tasks, where labeled data is scarce or difficult to obtain.
- Versatility: GANs can be applied to a wide range of tasks, including image synthesis, text-to-image synthesis, image-to-image translation, anomaly detection, data augmentation, and others.
Disadvantages of Generative Adversarial Networks (GANs):
- Training instability: GANs can be difficult to train, with the risk of instability, mode collapse, or failure to converge.
- Computational cost: GANs can require a lot of computational resources and can be slow to train, especially for high-resolution images or large datasets.
- Overfitting: GANs can overfit to the training data, producing synthetic data that is too similar to the training data and lacking diversity.
- Bias and fairness: GANs can reflect the biases and unfairness present in the training data, leading to discriminatory or biased synthetic data.
- Interpretability and accountability: GANs can be opaque and difficult to interpret or explain, making it challenging to ensure accountability, transparency, or fairness in their applications.
My Personal Notes
arrow_drop_up

















![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


