
Day 14:循環神經網路(Recurrent Neural Network, RNN) – iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天
Mục Lục
前言
上一篇我們對『自然語言處理』(Natural Language Processing, NLP)有一個初步的認識,現在,我們再進一步認識,如何以 Neural Network 處理語言的辨識。
循環神經網路(Recurrent Neural Network, RNN)
語言通常要考慮前言後語,以免斷章取義,也就是說,建立語言的相關模型,如果能額外考慮上下文的關係,準確率就會顯著提高,因此,學者提出『循環神經網路』(Recurrent Neural Network, RNN)演算法,它是『自然語言處理』領域最常使用的 Neural Network 模型,簡單的RNN模型(Vanilla RNN)額外考慮前文的關係,把簡單迴歸的模型 (y=W*x+b) ,改為下列公式,其中h就是預測值(y),同樣,將它加一個 Activation Function(通常使用 tanh),就變成第二個公式:
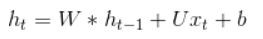
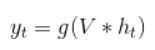
模型如下圖:
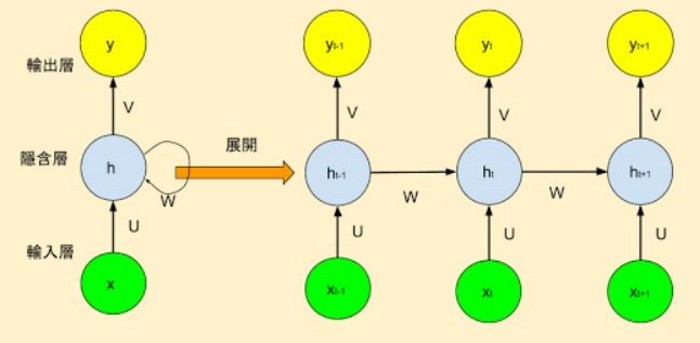
圖. RNN 模型,圖片來源 Ashing’s Blog_ 深度學習(3)–循環神經網絡(RNN, Recurrent Neural Networks)
也就是說,當前 output 不只受上一層輸入的影響,也受到同一層前一個 output 的影響(即前文),類似統計學的『時間數列』(Time Series),這個假設很合理,例如下面這兩個句子:
- 我不吃辣,所以,我點『蝦仁豆腐』
- 我吃辣 ,所以,我點『麻婆豆腐』
在分析『我點』的下一個詞時,若不考慮上下文, 『蝦仁豆腐』、 『麻婆豆腐』的機率是相等的,反之,考慮『我吃辣』,選『麻婆豆腐』的機率應該就會大於『蝦仁豆腐』。
另外,上述公式中的 W、U、V 都是權重,對應不同的輸入來源,與CNN一樣,基於『權重共享』(Shared Weights)或稱『參數共享』(Parameter Sharing)的假設,W、U、V 對每一點推導都共用,即使用相同的值,以簡化計算,之後同樣依據梯度下降法優化求解,這個模型就可以運作了。
另外,依據 input 及 output 的數目,RNN 可以有很多的變化與應用:
- 一對一(one to one):固定長度的輸入(input)及輸出(output),即一般的 Neural Network 模型。
- 一對多(one to many):單一輸入、多個輸出,例如影像標題(Image Captioning),輸入一個影像,希望偵測影像內多個物體,並一一給予標題,這稱之為『Sequence output』。
- 多對一(many to one):多個輸入、單一輸出,例如情緒分析(Sentiment Analysis),輸入一大段話,判斷這段話是正面或負面的情緒表達,這稱之為『Sequence input』。
- 多對多(many to many):多個輸入、多個輸出,例如語言翻譯(Machine Translation),輸入一段英文句子,翻譯成中文,這稱之為『Sequence input and sequence output 』。
- 另一種多對多(many to many):『同步』(Synchronize)的多個輸入、多個輸出,例如視訊分類(Video Classification),輸入一段影片,希望為每一幀(Frame)產生一個標題,這稱之為『Synced sequence input and output』。
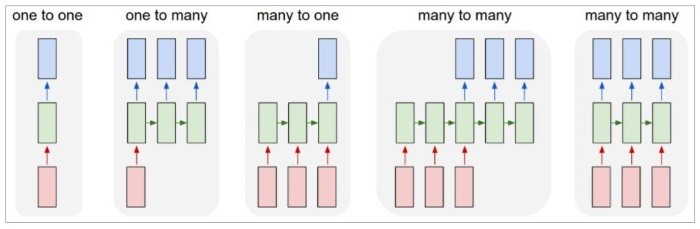
圖. RNN 模型,圖片來源 The Unreasonable Effectiveness of Recurrent Neural Networks
實作
為了先熟悉RNN的運作,我們還是用『阿拉伯數字辨識』來說明RNN函數,程式範例來自莫烦Python,同樣,把部分參數固定(Hard code)並加了一些註解,也可自這裡下載,檔名為RNN.py。
# 導入函式庫
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import SimpleRNN, Activation, Dense
from keras.optimizers import Adam
# 固定亂數種子,使每次執行產生的亂數都一樣
np.random.seed(1337)
# 載入 MNIST 資料庫的訓練資料,並自動分為『訓練組』及『測試組』
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 將 training 的 input 資料轉為3維,並 normalize 把顏色控制在 0 ~ 1 之間
X_train = X_train.reshape(-1, 28, 28) / 255.
X_test = X_test.reshape(-1, 28, 28) / 255.
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
# 建立簡單的線性執行的模型
model = Sequential()
# 加 RNN 隱藏層(hidden layer)
model.add(SimpleRNN(
# 如果後端使用tensorflow,batch_input_shape 的 batch_size 需設為 None.
# 否則執行 model.evaluate() 會有錯誤產生.
batch_input_shape=(None, 28, 28),
units= 50,
unroll=True,
))
# 加 output 層
model.add(Dense(units=10, kernel_initializer='normal', activation='softmax'))
# 編譯: 選擇損失函數、優化方法及成效衡量方式
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 一批訓練多少張圖片
BATCH_SIZE = 50
BATCH_INDEX = 0
# 訓練模型 4001 次
for step in range(1, 4001):
# data shape = (batch_num, steps, inputs/outputs)
X_batch = X_train[BATCH_INDEX: BATCH_INDEX+BATCH_SIZE, :, :]
Y_batch = y_train[BATCH_INDEX: BATCH_INDEX+BATCH_SIZE, :]
# 逐批訓練
loss = model.train_on_batch(X_batch, Y_batch)
BATCH_INDEX += BATCH_SIZE
BATCH_INDEX = 0 if BATCH_INDEX >= X_train.shape[0] else BATCH_INDEX
# 每 500 批,顯示測試的準確率
if step % 500 == 0:
# 模型評估
loss, accuracy = model.evaluate(X_test, y_test, batch_size=y_test.shape[0],
verbose=False)
print("test loss: {} test accuracy: {}".format(loss,accuracy))
# 預測(prediction)
X = X_test[0:10,:]
predictions = model.predict_classes(X)
# get prediction result
print(predictions)
# 模型結構存檔
from keras.models import model_from_json
json_string = model.to_json()
with open("SimpleRNN.config", "w") as text_file:
text_file.write(json_string)
# 模型訓練結果存檔
model.save_weights("SimpleRNN.weight")
程式執行
在DOS下,執行下列指令:
python RNN.py
程式說明
程式架構與之前程式大致相同,最大差別是隱藏層是採用 SimpleRNN,它的準確率達93%,因為,它額外考慮前面的像素關係,準確率自然比單純的 Neural Network 高一些,表示RNN確實有效果,另外,還有幾點要注意:
- 如果使用 Sequential 模型,且設定 batch_input_shape 維度,表示當批的output作為下一批的樣本初始狀態( initial states for the samples in the next batch),稱之為『stateful』。
- 如果要在後續的隱藏層要重置狀態(state),可呼叫.reset_states()。
- RNN 會考慮同一層前面的輸出,當參數 unroll=True 時,表示計算時會先展開結構,如下圖一,它會使用較多的記憶體,但會縮短計算時間,反之 unroll=False,如下圖二。
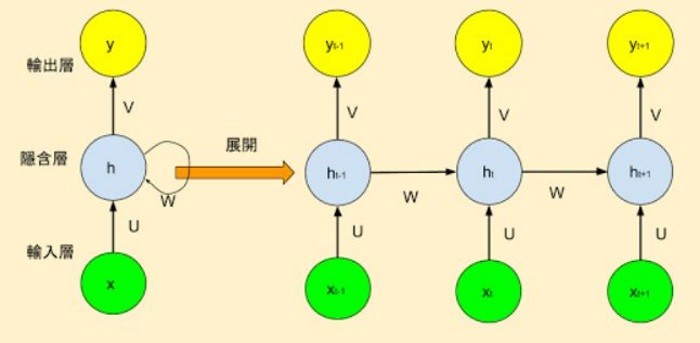
圖一. unroll=True,計算時會先展開結構,圖片來源 Ashing’s Blog_ 深度學習(3)–循環神經網絡(RNN, Recurrent Neural Networks)
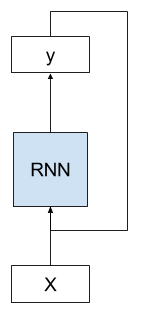
圖二. unroll=False,計算時不會先展開結構,資料來源:A Gentle Introduction to RNN Unrolling
眼尖的讀者可能會發覺,我們不是說過『要考慮前言後語,以免斷章取義』,而RNN只考慮前面的資料,沒有考慮後面的資料啊,是的,所以,另外有學者提出『雙向』(Bidirectional) RNN,見下圖,就是再加一層由後向前推估的模型,兩者綜合,即為雙向,Keras提供 Bidirectional() 函數實現此一功能,如下:
model.add(Bidirectional(SimpleRNN(10)))
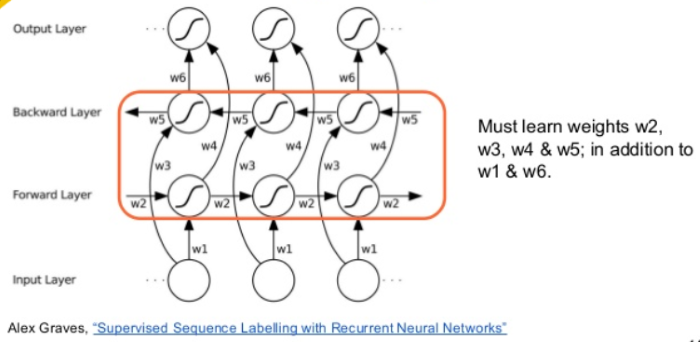
圖. 『雙向』(Bidirectional) RNN,資料來源:Recurrent Neural Networks (UPC 2016)
由於,單純使用RNN的應用不多,我們先介紹完另一個相關的演算法 LSTM 後,再一起討論相關應用,所以下一篇先討論『長短期記憶網路』(Long Short Term Memory Network, LSTM)吧。













![Toni Kroos là ai? [ sự thật về tiểu sử đầy đủ Toni Kroos ]](https://evbn.org/wp-content/uploads/New-Project-6635-1671934592.jpg)


